linux中iowait的形成原因和内核分析
经常我们碰到一些问题,进程的写文件,写入的速度非常慢,而且当时总的IO的数量(BI,BO)也非常低,但是vmstat显示的iowait却非常高,就是下图中的wa选项。
iowait_oenhan
man vmstat手册如下解释:

wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
CPU花费到IO等待上的时间,也就是说进程的io被CPU调度出去了,并没有进行立即执行,导致整个执行时间延长,程序性能降低。
那么wa是如何统计的呢?
vmstat是procps内实现的
oenhan@oenhan ~ $ dpkg-query -S /usr/bin/vmstat
procps: /usr/bin/vmstat
在procps中,wa中通过getstat读取/proc/stat实现的。
void getstat(jiff *restrict cuse, jiff *restrict cice,
jiff *restrict csys, jiff *restrict cide,
jiff *restrict ciow, jiff *restrict cxxx,
jiff *restrict cyyy, jiff *restrict czzz,
unsigned long *restrict pin, unsigned long *restrict pout,
unsigned long *restrict s_in,unsigned long *restrict sout,
unsigned *restrict intr, unsigned *restrict ctxt,
unsigned int *restrict running, unsigned int *restrict blocked,
unsigned int *restrict btime, unsigned int *restrict processes)
{
static int fd;
unsigned long long llbuf = 0;
int need_vmstat_file = 0;
int need_proc_scan = 0;
const char* b;
buff[BUFFSIZE-1] = 0; /* ensure null termination in buffer */
if(fd){
lseek(fd, 0L, SEEK_SET);
}else{
fd = open("/proc/stat", O_RDONLY, 0);
if(fd == -1) crash("/proc/stat");
}
read(fd,buff,BUFFSIZE-1);
*intr = 0;
*ciow = 0; /* not separated out until the 2.5.41 kernel */
*cxxx = 0; /* not separated out until the 2.6.0-test4 kernel */
*cyyy = 0; /* not separated out until the 2.6.0-test4 kernel */
*czzz = 0; /* not separated out until the 2.6.11 kernel */
b = strstr(buff, "cpu ");
if(b) sscanf(b, "cpu %Lu %Lu %Lu %Lu %Lu %Lu %Lu %Lu",
cuse, cice, csys, cide, ciow, cxxx, cyyy, czzz);
proc/stat在内核中通过show_stat实现,统计cpustat.iowait获取最终结果:
iowait = cputime64_add(iowait, get_iowait_time(i));
static cputime64_t get_iowait_time(int cpu)
{
u64 iowait_time = -1ULL;
cputime64_t iowait;
if (cpu_online(cpu))
iowait_time = get_cpu_iowait_time_us(cpu, NULL);
if (iowait_time == -1ULL)
/* !NO_HZ or cpu offline so we can rely on cpustat.iowait */
iowait = kstat_cpu(cpu).cpustat.iowait;
else
iowait = usecs_to_cputime64(iowait_time);
return iowait;
}
而cpustat.iowait的值在account_system_time统计计算,通过统计rq->nr_iowait的值判断来递增。
void account_system_time(struct task_struct *p, int hardirq_offset,
cputime_t cputime)
{
struct cpu_usage_stat *cpustat = &kstat_this_cpu.cpustat;
runqueue_t *rq = this_rq();
cputime64_t tmp;
p->stime = cputime_add(p->stime, cputime);
/* Add system time to cpustat. */
tmp = cputime_to_cputime64(cputime);
if (hardirq_count() - hardirq_offset)
cpustat->irq = cputime64_add(cpustat->irq, tmp);
else if (softirq_count())
cpustat->softirq = cputime64_add(cpustat->softirq, tmp);
else if (p != rq->idle)
cpustat->system = cputime64_add(cpustat->system, tmp);
else if (atomic_read(&rq->nr_iowait) > 0)
cpustat->iowait = cputime64_add(cpustat->iowait, tmp);
else
cpustat->idle = cputime64_add(cpustat->idle, tmp);
/* Account for system time used */
acct_update_integrals(p);
}
附加一句:account_system_time可以用来具体统计更详细的CPU占用情况。
而控制的rq->nr_iowait的函数是io_schedule和io_schedule_timeout。
void __sched io_schedule(void)
{
struct runqueue *rq = &per_cpu(runqueues, raw_smp_processor_id());
delayacct_blkio_start();
atomic_inc(&rq->nr_iowait);
schedule();
atomic_dec(&rq->nr_iowait);
delayacct_blkio_end();
}
long __sched io_schedule_timeout(long timeout)
{
struct runqueue *rq = &per_cpu(runqueues, raw_smp_processor_id());
long ret;
delayacct_blkio_start();
atomic_inc(&rq->nr_iowait);
ret = schedule_timeout(timeout);
atomic_dec(&rq->nr_iowait);
delayacct_blkio_end();
return ret;
}
因为没有实际应用场景,针对调用代码做一下分析,具体的应用场景可以参考
查看调用代码如下:
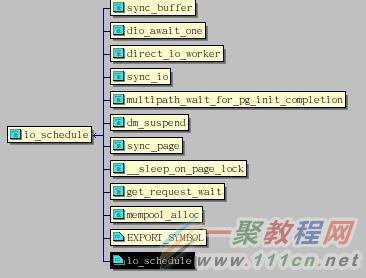
先看io_schedule函数,调用它的有sync_buffer,sync_io,dio_awit_one,direct_io_worker,get_request_wait等,只要你有对磁盘的写入操作,就会调用io_schedule,尤其以直接写入(DIO)最明显,每次写入都会调用。普通写入也只是积攒到buffer里面,统一刷新buffer的时候才会调用一次io_schedule。即使没有主动的写入IO,也有可能产生iowait,在sync_page函数中,当缓存和硬盘数据进行同步的时候,就会被调用,比如常用的mlock锁内存时就会__lock_page触发缓存同步,一样会增加iowait,一些读硬盘也会触发。

虽然io_schedule调用的非常多,但真正的大杀器还是io_schedule_timeout,io_schedule由内核调用,整个调度时间还是比较短的,io_schedule_timeout则基本都是指定了HZ/10的时间段。如balance_dirty_pages中每次写入文件都会对脏页进行平衡处理,wb_kupdate定时器般进行缓存刷新,try_to_free_pages则在释放内存时刷缓存时使用,虽然不是每次都使用io_schedule_timeout,但综合各个的判断条件看,当内存中的缓存足够多的时候,会极大触发io_schedule_timeout,水线一般是dirty_background_ratio和dirty_ratio。
如上所分析的,避免iowait需要注意的有:
1.高性能要求的进程最好在内存中一次读完所有数据,全部mlock住,不需要后面再读磁盘,
2.不需要写或者刷新磁盘(一般搞不定,就让单独的进程专门干这个活)。
3.控制整个缓存的使用情况,但从工程上不容易处理,虚拟化估计更有效,相对与系统虚拟化(KVM),进程虚拟化(cgroup)应该更简单有效。
相关文章
-
沐曦股份曦云C系列GPU产品深度适配了美团新一代万亿参数大模型LongCat-2.0
游戏攻略 2026-07-14
-
AI+机器人千亿赛道爆发:FPGA大厂Altera预计 2026年营收迎强势增长
游戏攻略 2026-07-14
-
摩尔线程极速完成美团LongCat-2.0大模型适配
游戏攻略 2026-07-14
-
用经典本体论工具栈去逆向解释Palantir:是一种方法论上的时代错位
游戏攻略 2026-07-14
-
AI技术坟场——没有系统思维的企业管理智能化部署:就是一场灾难!
游戏攻略 2026-07-14
-
LangChain OpenAI 1.3.5发布:支持显式提示缓存功能
游戏攻略 2026-07-14