Python爬取淘宝模特图片网络爬虫示例
为了爬取模特的图片,我们首先要找到各个模特自己的页面。通过查看网页源码,我们可以发现,模特各自的页面的特点如下:

我们可以通过查找class属性为lady-name的标签,然后取其href属性来获取各个模特各自的页面地址。
1 html = urlopen(url)
2 bs = BeautifulSoup(html.read().decode('gbk'),"html.parser")
3 girls = bs.findAll("a",{"class":"lady-name"})
4 for item in girls:
5 linkurl = item.get('href')
继续分析模特各自的页面的特点,模特页面打开后的页面布局如下:
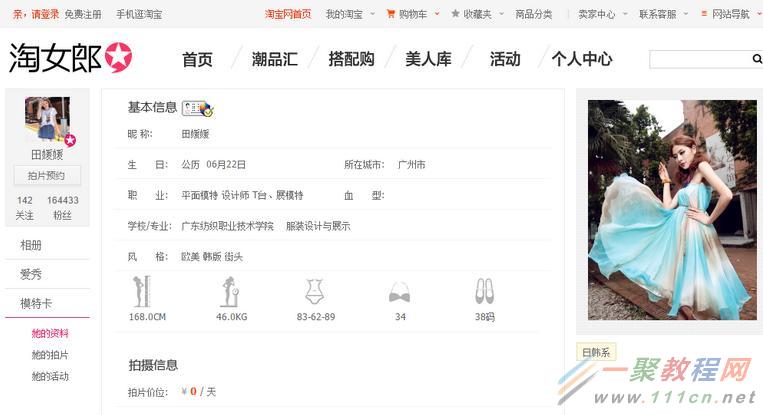
在这个页面中我们要提取的是模特的个性域名,这个域名打开后,里面就有模特的图片了。那么我们的关键问题就是如何提取这个域名。按我们之前的学习,我们会去查找这个标签,但是我们打开网页源码会发现网页源码里面并没有包含这个信息。这是因为这一部分的信息是用JS动态生成的。那么这种情况下我们怎么办呢?
答案是使用selenium和PhantomJS,相关的概念可以自行百度。简而言之,PhantomJS是一个无界面的浏览器,而selenium是一个测试浏览器的工具,结合这2者,我们就可以解析动态的页面了。

获取模特的个性域名的代码如下:
复制代码
1 def getUrls(url):
2 driver= webdriver.PhantomJS()
3 html = urlopen(url)
4 bs = BeautifulSoup(html.read().decode('gbk'),"html.parser")
5 girls = bs.findAll("a",{"class":"lady-name"})
6 namewithurl = {}
7 for item in girls:
8 linkurl = item.get('href')
9 driver.get("https:"+linkurl)
10 bs1 = BeautifulSoup(driver.page_source,"html.parser")
11 links = bs1.find("div",{"class":"mm-p-info mm-p-domain-info"})
12 if links is not None:
13 links = links.li.span.get_text()
14 namewithurl[item.get_text()] = links
15 print(links)
16 return namewithurl
复制代码
在这里,我们使用PhantomJs去加载动态的页面,然后用BeautifulSoup去规则化加载后的页面,接下来的工作就与普通的网页相同了。
接下来分析模特的个人主页的特点,直观上是这样的页面:
分析源码后我们会发现,模特的图片地址可以这样获取:
1 html = urlopen(personurl)
2 bs = BeautifulSoup(html.read().decode('gbk'),"html.parser")
3 contents = bs.find("div",{"class":"mm-aixiu-content"})
4 imgs = contents.findAll("img",{"src":re.compile(r'//img.alicdn.com/.*.jpg')})
如此我们就能获取模特的个人域名地址中的图片了,接下来的问题就是如何保存图片了。
我们可以用urllib中的urlretrieve函数来完成保存的工作。
用法为urlretrieve(imgurl, savepath)
再加入多线程等代码,完整的爬虫代码为:
| 代码如下 | 复制代码 |
|
#coding = utf-8 savepath=r".save" def mkdir(path): def getUrls(url): def getImgs(parms): if __name__ == "__main__": |
|
然后打开里面会有你想不到的结果哦,所以的图片全部自动下载成功哦。