12c的asm中混搭11g DB和12c DB,报错ora-600
客户的一个数据库,是12c的cluster环境,这个环境中有11g的db和12c的db。当客户准备在一个diskgroup上的数据库拉起来的时候(这个cluster是放多个测试库,是从几十个生产库的disk通过存储级复制的方式,集中起来的。生产库那边一个cluster只有一个database,只有2个diskgroup(DATA和FRA),但是这个测试库集中了多个生产库,所以上面有70个多diskgroup),报错了:
ORA-15001:diskgroup "DATA_MIDG" does not exist or is not mounted
ORA-00600:internal error code, arguments: [kfnSlaveGroupUse], [KFGN_MAX], [67], [3352857312], [], [], [], [], [], [], [], []
而实际上,这个DATA_MIDG是存在的,在asm中查,状态也是mount的。
这其实是因为Bug 19404632 GRID 12.1 ASM with DB 11.2 hits ORA600 [kfnSlaveGroupUse] [KFGN_MAX] when # of ASM disk groups > 63 (Doc ID 19404632.8)
虽然,在12c中,diskgroup的数量已经可以达到511个,但是这需要数据库的版本的配合,数据库必须是12c,才可以用到diskgroup number 64之后的diskgroup。如果数据库是11g,那么在diskgroup number是63(含)之前,是可以用的;diskgroup number是64之后,就会遭遇到上面的ora-600 [kfnSlaveGroupUse],[KFGN_MAX], [67]的报错。这里的67,表示第67号diskgroup number,也就是我controlfile所在的+DATA_MIDG。
在bug的内部文档也说了KfnsGorupUse函数会拒绝如果database版本小于12c,且已经有超过63的diskgroup number的数据库使用大于63号diskgroup numeber的盘。这是hardcode在代码中的,无法通过某个隐含参数进行调节:
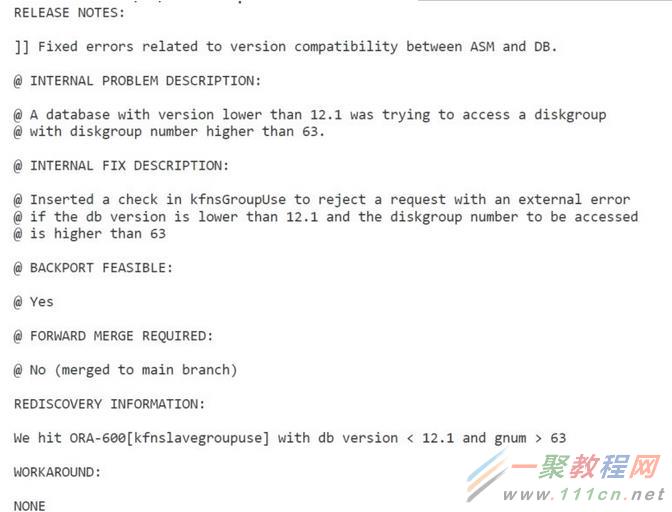
目前虽然有Patch 19404632,但是这个补丁只是将ora-600的报错信息,转换成meaningful message,实际还是需要database版本为12c。
所以我们可以做的事情是,提前做好规划,对于这种12c的asm混搭11g DB和12c DB,尽量让11g DB用63号之前的diskgroup,而12c DB用64号之后的diskgroup。这可能就需要我们提前建立几个diskgroup进行“占坑”。