MongoDB数据库index索引的用法和作用
索引最大的作用就是提高query的查询性能,如果没有索引,mongodb需要scan整个collection的所有的documents,并筛选符合条件的document,如果有索引,那么query只需要遍历index中有限个索引条目即可,况且index中的条目是排序的,这对“order by”操作也非常有利。
索引:特殊的数据结构,存储表的数据的一小部分以实现快速查询
优点:
1、大大减少了服务器需要扫描的数据量
2、索引可以帮助服务器避免排序或使用临时表
3、索引可以将随机io转换为顺序io
索引评估:三星(非常好)
一星:索引如果能将相关的记录放置到一起
二星:索引中数据的存储顺序与查找标准中顺序一致
三星:如果索引中包含查询中所需要的全部数据:(覆盖索引)
DBA书:关系型数据库索引设计与优化
索引类别:
顺序索引
散列索引:将索引映射至散列桶上,映射是通过散列函数进行的
评估索引的标准:
访问类型:做等值比较用散列索引,用范围比较时用顺序索引
访问时间:
插入时长:
删除时长:
空间开销:
顺序索引:
聚集索引:如果某记录文件中的记录顺序是按照对应的搜索码指定的顺序排序,聚集索引页成为主索引
非聚集索引:搜索码中的指定的次序与记录文件中的记录次序不一致
有聚集索引的数据文件,也叫做索引顺序文件
根据索引中是否为每个记录相应的创建索引项,可分为稠密索引和稀疏索引
多级索引:(但对频繁修改的数据,性能很差)
辅助索引必须是稠密索引
B+树索引:顺序索引
Balance Tree:平衡树索引
顺序索引的特性:
全值匹配:Name='user12'
匹配最左前缀:Name LIKE 'User1%',无效:Name LIKE '%User1%'
匹配列前缀:Name LIKE 'User1%',无效:Name LIKE '%User1%'
匹配范围值
精确匹配某一列并范围匹配另外一列:
只访问索引的查询
散列索引:
散列函数:
分布随机
分布均匀
适用场景:
精确匹配:=,IN(),<=>
Mysql:全文索引,fulltext
sphinx,lucene
空间索引:必须使用空间索引函数获取相应的查询结果
主键、唯一键
Mysql:创建索引
create index index_name on table (col1,…) alter table add index alter table drop index drop index index_name from table show indexes from table
Mongodb创建索引:
id字段就有主索引
在Name创建索引:

查看所有:
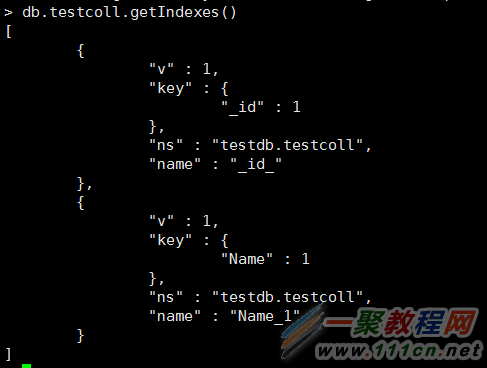
默认在id上创建了主索引
唯一索引:
db.collection.ensureIndex({"user_id":1},{unique:true})
sparse index:稀疏索引
db.collection.ensureIndex({"user_id":1},{sparse:true})
Mongodb:
索引可以创建在collection上,也可以创建在子文档中
Mongodb索引类型:
单键索引
组合索引
多键索引:
空间索引
文本索引
hash索引
hash索引:
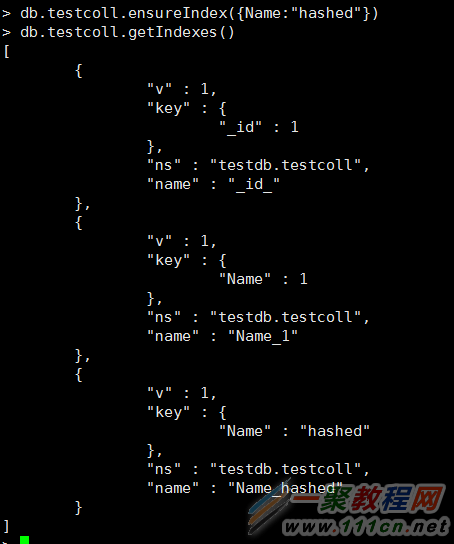
删除索引:
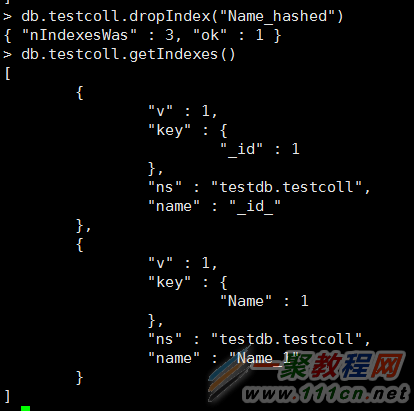
或者
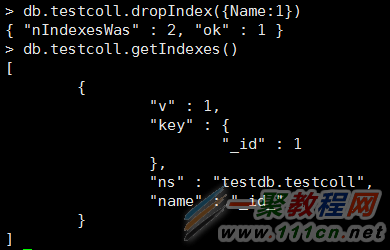
db.mycoll.dropIndexes():删除mycoll的所有索引
查询过程:explain
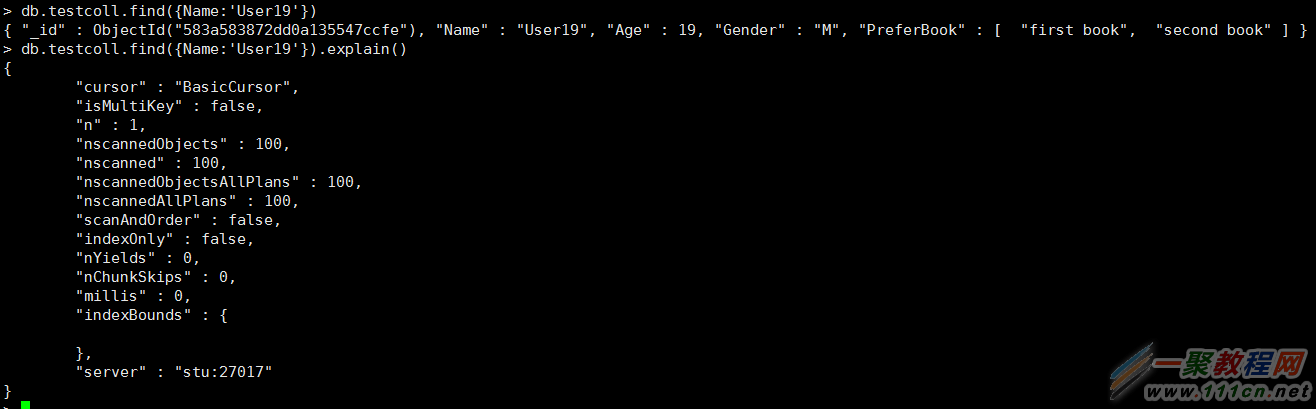
扫描了100个数据
创建索引后,只扫描一个数据
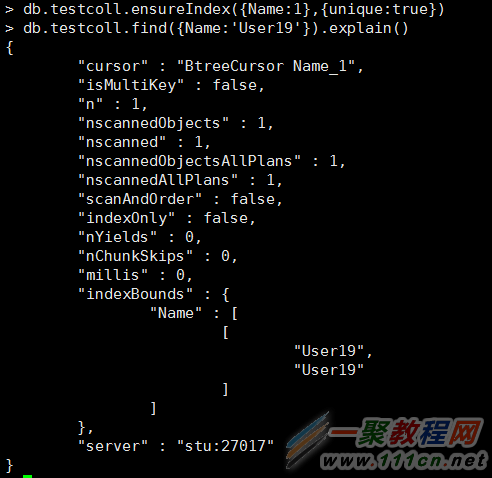
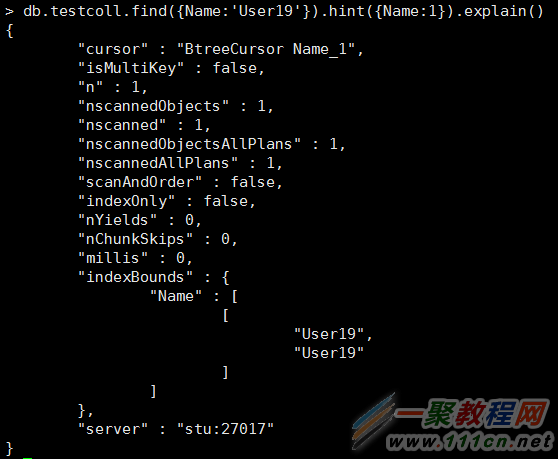
指定索引:
创建组合索引:
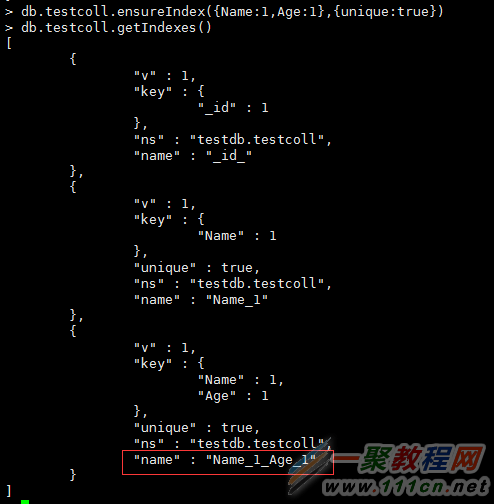
通过组合索引查询:
> db.testcoll.find({Name:'User19'}).hint({Name:1,Age:1}).explain()
{
"cursor" : "BtreeCursor Name_1_Age_1",
"isMultiKey" : false, "n" : 1,
"nscannedObjects" : 1,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 1,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" :
{
"Name" :
[
[
"User19",
"User19"
]
],
"Age" :
[
[
{
"$minElement" : 1
},
{
"$maxElement" : 1
}
]
]
},
"server" : "stu:27017"
}