MySQL服务器 IO 100%的分析与优化方案
前言
压力测试过程中,如果因为资源使用瓶颈等问题引发最直接性能问题是业务交易响应时间偏大,TPS逐渐降低等。而问题定位分析通常情况下,最优先排查的是监控服务器资源利用率,例如先用TOP 或者nmon等查看CPU、内存使用情况,然后在排查IO问题,例如网络IO、磁盘IO的问题。 如果是磁盘IO问题,一般问题是SQL语法问题、MYSQL参数配置问题、服务器自身硬件瓶颈导致IOPS吞吐率问题。
本文主要给大家介绍的是关于MySQL服务器 IO 100%的分析与优化方案,下面话不多说了,来一起看看详细的介绍吧
【问题】
有台MySQL 5.6.21的数据库实例以写入为主,IO %util接近100%
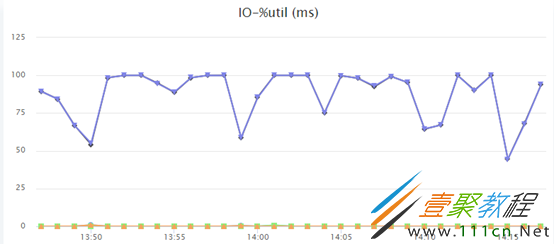
写入IOPS很高

【分析过程】
1、通过iotop工具可以看到当前IO消耗最高的mysql线程
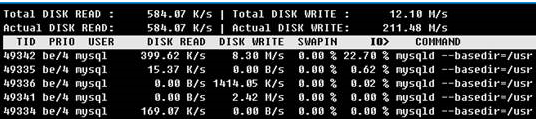
2、查看线程49342的堆栈,可以看到正在进行redo log的刷新,对应的是9号文件
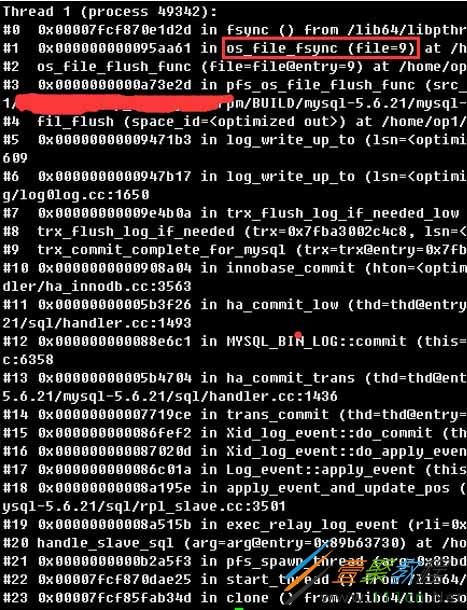
3、9号文件对应的是redo log的第一个文件

为什么mysql进程会频繁的刷新redo log文件,要结合redolog的刷盘策略来分析,关键是innodb_flush_log_at_trx_commit参数,
默认是1,最安全,但在写压力大的情况下,也会带来较大的性能影响,每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去。
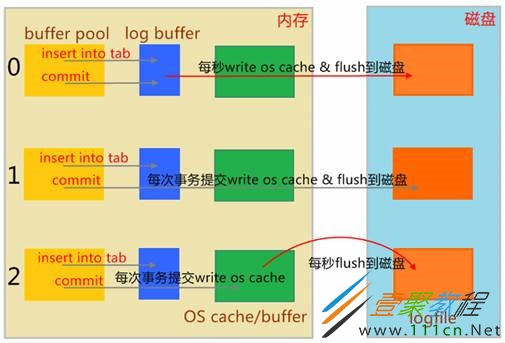
结合这个集群的写入场景来看,大部分都是小事务的写入,每次事务提交都会触发刷盘动作,这种场景下通过增大innodb_log_buffer_size和innodb_log_file_size的优化效果不明显
【优化方案】
1、应用层面,对于写压力大的系统,可以将单条的insert语句优化为小批量的insert语句,这样事务commit的次数减少,redo log刷盘减少,性能理论上会有提升
2、MySQL层面,对于日志类型的系统,如果允许宕机的情况下少量数据丢失,可以将innodb_flush_log_at_trx_commit参数调整为2,
当设置为2时,则在事务提交时只做write操作,只保证写到系统的page cache,因此实例crash不会丢失事务,但宕机则可能丢失事务
在这台服务器上测试,将参数调整为2时,IO的请求从200M/S降到约10M/S压力会减少10倍以上

3、系统层面,更换性能更佳的磁盘