Mysql覆盖索引怎么样 Mysql覆盖索引详解
本篇文章小编给大家分享一下Mysql覆盖索引详解,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
概念
如果索引包含所有满足查询需要的数据的索引成为覆盖索引(Covering Index),也就是平时所说的不需要回表操作
判断标准
使用explain,可以通过输出的extra列来判断,对于一个索引覆盖查询,显示为using index,MySQL查询优化器在执行查询前会决定是否有索引覆盖查询
注意
1、覆盖索引也并不适用于任意的索引类型,索引必须存储列的值
2、Hash 和full-text索引不存储值,因此MySQL只能使用B-TREE
3、并且不同的存储引擎实现覆盖索引都是不同的
4、并不是所有的存储引擎都支持它们
5、如果要使用覆盖索引,一定要注意SELECT 列表值取出需要的列,不可以是SELECT *,因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降,不能为了利用覆盖索引而这么做
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引'。即只需扫描索引而无须回表。
只扫描索引而无需回表的优点:
1.索引条目通常远小于数据行大小,只需要读取索引,则mysql会极大地减少数据访问量。
2.因为索引是按照列值顺序存储的,所以对于IO密集的范围查找会比随机从磁盘读取每一行数据的IO少很多。
3.一些存储引擎如myisam在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用
4.innodb的聚簇索引,覆盖索引对innodb表特别有用。(innodb的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询)
覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引不存储索引列的值,所以mysql只能用B-tree索引做覆盖索引。
当发起一个索引覆盖查询时,在explain的extra列可以看到using index的信息
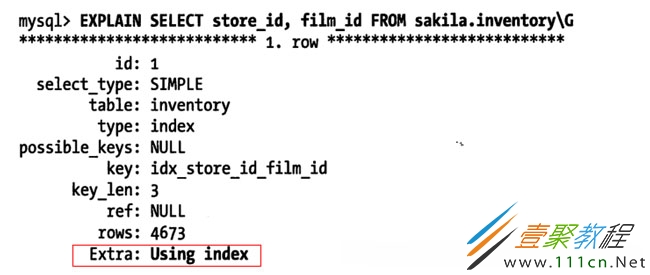
覆盖索引的坑:mysql查询优化器会在执行查询前判断是否有一个索引能进行覆盖,假设索引覆盖了where条件中的字段,但不是整个查询涉及的字段,mysql5.5和之前的版本也会回表获取数据行,尽管并不需要这一行且最终会被过滤掉。

如上图则无法使用覆盖查询,原因:
1.没有任何索引能够覆盖这个索引。因为查询从表中选择了所有的列,而没有任何索引覆盖了所有的列。
2.mysql不能在索引中执行LIke操作。mysql能在索引中做最左前缀匹配的like比较,但是如果是通配符开头的like查询,存储引擎就无法做比较匹配。这种情况下mysql只能提取数据行的值而不是索引值来做比较
优化后SQL:添加索引(artist,title,prod_id),使用了延迟关联(延迟了对列的访问)

说明:在查询的第一阶段可以使用覆盖索引,在from子句中的子查询找到匹配的prod_id,然后根据prod_id值在外层查询匹配获取需要的所有值。
5.5时API设计不允许mysql将过滤条件传到存储引擎层(是把数据从存储引擎拉到服务器层,在根据条件过滤),5.6之后由于ICP这个特性改善了查询执行方式
当MySQL不能使用索引进行排序时,就会利用自己的排序算法(快速排序算法)在内存(sort buffer)中对数据进行排序,如果内存装载不下,它会将磁盘上的数据进行分块,再对各个数据块进行排序,然后将各个块合并成有序的结果集(实际上就是外排序)
对于filesort,MySQL有两种排序算法
1、两遍扫描算法(Two passes)
实现方式是先将须要排序的字段和可以直接定位到相关行数据的指针信息取出,然后在设定的内存(通过参数sort_buffer_size设定)中进行排序,完成排序之后再次通过行指针信息取出所需的Columns
注:该算法是4.1之前采用的算法,它需要两次访问数据,尤其是第二次读取操作会导致大量的随机I/O操作。另一方面,内存开销较小
2、 一次扫描算法(single pass)
该算法一次性将所需的Columns全部取出,在内存中排序后直接将结果输出
注: 从 MySQL 4.1 版本开始使用该算法。它减少了I/O的次数,效率较高,但是内存开销也较大。如果我们将并不需要的Columns也取出来,就会极大地浪费排序过程所需要 的内存。在 MySQL 4.1 之后的版本中,可以通过设置 max_length_for_sort_data 参数来控制 MySQL 选择第一种排序算法还是第二种。当取出的所有大字段总大小大于 max_length_for_sort_data 的设置时,MySQL 就会选择使用第一种排序算法,反之,则会选择第二种。为了尽可能地提高排序性能,我们自然更希望使用第二种排序算法,所以在 Query 中仅仅取出需要的 Columns 是非常有必要的。
当对连接操作进行排序时,如果ORDER BY仅仅引用第一个表的列,MySQL对该表进行filesort操作,然后进行连接处理,此时,EXPLAIN输出“Using filesort”;否则,MySQL必须将查询的结果集生成一个临时表,在连接完成之后进行filesort操作,此时,EXPLAIN输出 “Using temporary;Using filesort”