mysql利用覆盖索引避免回表优化查询代码示例
本篇文章小编给大家分享一下mysql利用覆盖索引避免回表优化查询代码示例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
说到覆盖索引之前,先要了解它的数据结构:B+树。
先建个表演示(为了简单,id按顺序建):
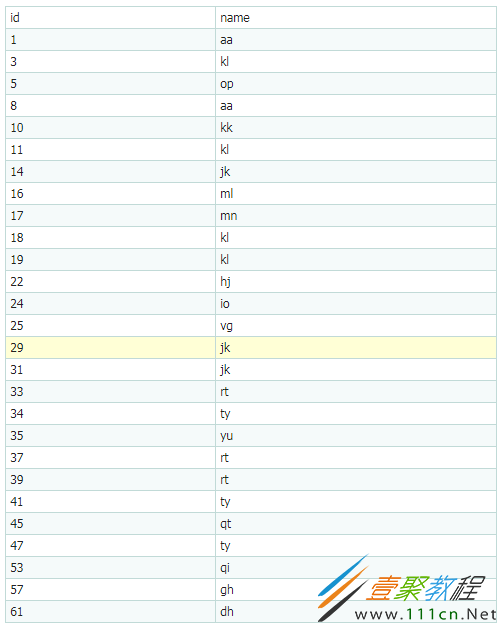
以主键以外的列值作为键值构建的 B+ 树索引,我们称之为非聚集索引。
非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
B+树
B+树和B树是mysql索引的常用数据结构,B+树是B树的进一步优化,将上面的表转成图分析一下:

B+树的特点:
1.B+ 树非叶子节点上是不存储数据的,仅存储键值
2.叶子节点的数据是按照顺序排列的
3. B+ 树中各个页之间是通过双向链表连接
聚簇索引和非聚簇索引
B+ 树索引按照存储方式的不同分为聚集索引和非聚集索引。
聚簇索引:
以 InnoDB 作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。
这是因为 InnoDB 是把数据存放在 B+ 树中的,而 B+ 树的键值就是主键,在 B+ 树的叶子节点中,存储了表中所有的数据。
这种以主键作为 B+ 树索引的键值而构建的 B+ 树索引,我们称之为聚集索引。
非聚簇索引:
以主键以外的列值作为键值构建的 B+ 树索引,我们称之为非聚集索引。
非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
如何用覆盖索引避免回表
为什么明明用了非主键索引还会回表,简单说就是非主键索引是非聚簇索引,在B+树叶子节点中只保存主键和该非主键索引,一次查询只能查到这两个字段,如果想查三个字段,就必须再查一次聚簇索引,这就是回表。
举个例子,表中新增一个字段age,我们用name建一个索引(非聚簇索引)
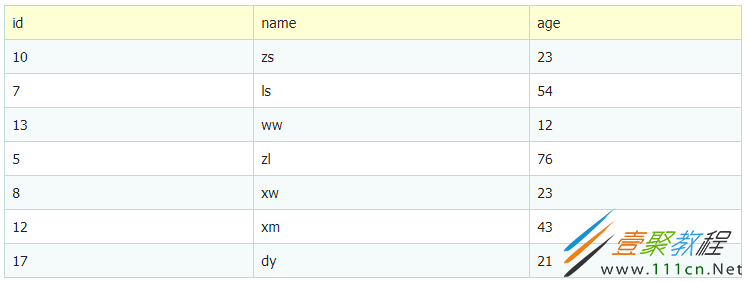
select id,name from user where name = 'zs';
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
select id,name,age from user where name = 'zs';
能够命中name索引,索引叶子节点存储了主键id,但age字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取age字段,效率会降低。
结论:那怎么做才能避免回表呢?很简单,将单列索引(name)升级为联合索引(name,age).