Pandas实现分组计数且不计重复代码示例
作者:袖梨
2022-06-25
本篇文章小编给大家分享一下Pandas实现分组计数且不计重复代码示例,文章介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
在对dataframe进行分析的时候会遇到需要分组计数,计数的column中属性有重复,但又需要仅对不重复的项计数(即重复N次出现的项只计1次)。
函数如下:
dataframe.groupby([‘分组的列名']).需要计数的列名.nunique()
举例:
数组“data”如下:
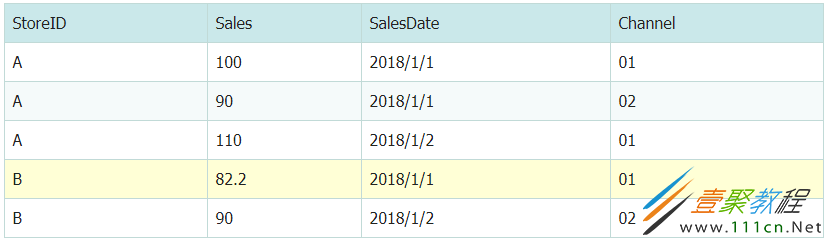
如果要按StoreID来统计每一家店的营业日期数(可以通过不计重复的count “SalesDate”来完成)
代码如下:
data.groupby(['StoreID']).SalesDate.nunique()
补充:pandas 统计分组内不重复计数
在数据分析中的数据处理过程中,经常需要对数据进行分组计数,看下下面这组数据
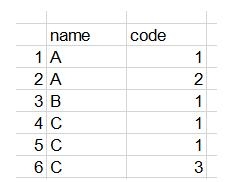
数据中name 为C 的有三行,其中有2个code是重复的
目标:
按name 分组,统计每组中code的不重复数量
df.groupby('name')['code'].nunique()
# 以name 分组后,统计code的不重复数目
结果如下:
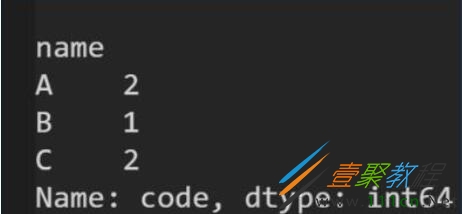
排序
df.groupby('name')['code'].nunique().sort_values(ascending=False)
# 以name 分组后,统计code的不重复数目