用Python下载抖音无水印视频代码示例
作者:袖梨
2022-06-25
本篇文章小编给大家分享一下用Python下载抖音无水印视频代码示例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
一、获取抖音视频连接

得到如下信息: “5.1 HV:/ 守门员戴手套没法系鞋带这种体育精神,值得尊敬%遇见足球 %足球 %精彩进球 %意甲 %唯有足球不 https://v.dou**y*in.com/eDFd28P/ 复制此链接,打开Dou音搜索,直接观看视频!”
通过正则取到信息中的地址:
share_url='5.1 HV:/ 守门员戴手套没法系鞋带这种体育精神,值得尊敬%遇见足球 %足球 %精彩进球 %意甲 %唯有足球不 https://v.dou**y*in.com/eDFd28P/ 复制此链接,打开Dou音搜索,直接观看视频!'
short_url = re.findall('(https?://[^s]+)', share_url)[0]
二、访问地址对返回的数据进行分析
通过访问得到的短连接,请求的地址会变成下面的

然后分析返回的数据:
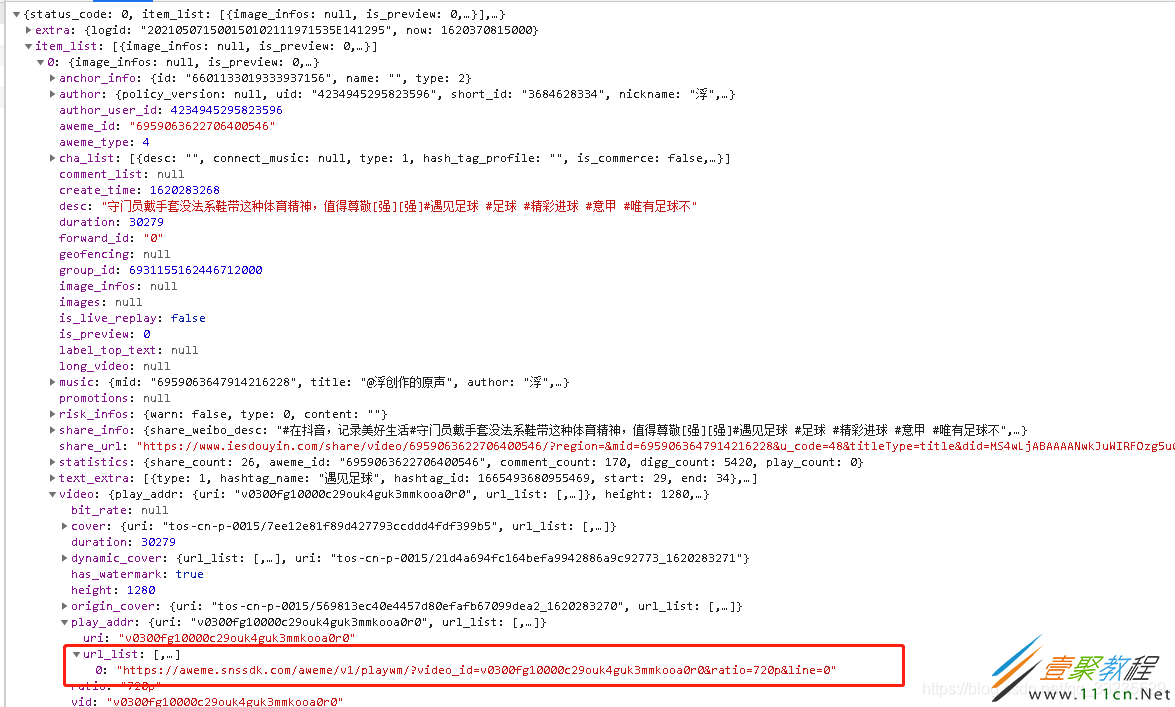
对返回的数据逐个筛选,发现这个连接可以直接访问到视频
对请求的地址重新整理获取源视频的地址:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
}
# 通过分享连接获取跳转的地址
url = requests.get(url=short_url,headers=headers).url
# 通过跳转的地址找到item_id
item_id = re.findall('https://www.iesdo**u*yin.com/share/video/(d+)',url)[0]
# 请求地址获取数据
rel_url = requests.get(url="https://www.ies*do**uyin.com/web/api/v2/aweme/iteminfo/?item_ids="+item_id,headers=headers).text
# 筛出视频地址
video_rul = json.loads(rel_url)['item_list'][0]['video']['play_addr']['url_list'][0]
三、如何去除水印
以上步骤中可以得到视频的地址:https://aweme.sn**ss*dk.com/aweme/v1/playwm/?video_id=v0300fg10000c29ouk4guk3mmkooa0r0&ratio=720p&line=0将其中的playwm替换为play就可以得到没有水印的地址
video_rul = json.loads(rel_url)['item_list'][0]['video']['play_addr']['url_list'][0].replace('/playwm/', '/play/')
四、整合代码
import requests
import re
import json
down_load_path = 'E:下载的MP4'
class D_y():
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
}
def __init__(self,share_url):
self.share_url = share_url
def get_rel_url(self):
# short_url = re.findall('(https?://[^s]+)', self.share_url)[0]
short_url = re.findall('(http[|s]?://[^s]*/)', self.share_url)[0]
url = requests.get(url=short_url, headers=self.headers).url
# item_id = re.findall('https://www.*ie*sdouyi*n.com/share/video/(d+)', url)[0]
item_id = url.split('/')[5]
rel_url = requests.get(url="https://www.ies*do**uyin.com/web/api/v2/aweme/iteminfo/?item_ids=" + item_id,headers=self.headers).text
video_rul = json.loads(rel_url)['item_list'][0]['video']['play_addr']['url_list'][0].replace('/playwm/','/play/')
video = requests.get(url=video_rul,headers=self.headers).content
video_name = json.loads(rel_url)['item_list'][0]['share_info']['share_title'].split('#')[0].split('@')[0].replace(' ','')
with open(down_load_path+str(video_name)+'.mp4','wb') as f:
f.write(video)
f.close()
print("【抖音短视频】: {}.mp4 无水印视频下载完成!".format(video_name))
if __name__ == '__main__':
a = input("url:")
D_y(a).get_rel_url()