Java String保存字符串机制代码示例
本篇文章小编给大家分享一下Java String保存字符串机制代码示例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
String 真的是 Immutable 的吗
Java 中的 Unicode 字符串会按照 Latin1(所有的字符都小于 0xFF 时)或者 UTF16 的编码格式保存在 String 中,保存为 byte 数组:
private final byte[] value;
通常所说的 Immutable 都是指 final bytes 在 String 初始化后就不会修改,所有字符串的相关操作都是不会修改原数组而是创建新的副本。
但是数组元素理论上是可以修改的,比如下面通过反射的方式,将字符串常量 abc 修改为 Abc:
public static void main(String[] args) {
setFirstValueToA("abc");
String replaced = new String("abc");
System.out.println(replaced); // Abc
}
private static void setFirstValueToA(String str) {
Class stringClass = String.class;
try {
Field value = stringClass.getDeclaredField("value");
value.setAccessible(true);
byte[] bytes = (byte[]) value.get(str);
bytes[0] = 0x41; // A
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
}
字符串数组如何保存为字节数组
通过如下代码测试几个字符串数组:
public static void main(String[] args) {
printString("abc");
printString("中文");
printString("abc中文");
printString("abc");
}
private static void printString(String str) {
System.out.println("======>" + str);
// return the UTF-16 char[] size
System.out.println("length: " + str.length());
// Use default Encoding (UTF-8)
System.out.println("getBytes: " + str.getBytes().length);
// Convert UTF-16 char[] to char
System.out.println("codePointCount: " + str.codePointCount(0, str.length()));
// Get the UTF-16 char[]
System.out.println("toCharArray: " + str.toCharArray().length);
// The UTF-16 char[] to bytes
System.out.println("internal value: " + getStringInternalValueLength(str));
}
结果如下:
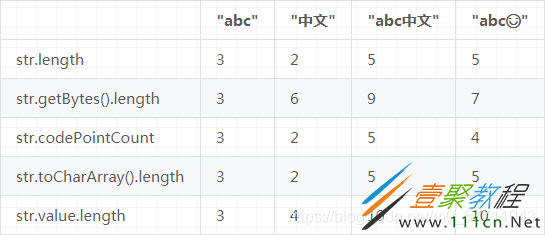
internal value
首先解释下 String 的 value 字段计算方式:
所有字符都小于 0xFF 时,采用 Latin1 Character Encoding 来保存 Unicode code point,也就是每个字符都用一个 byte 来保存。比如“ABC”
上述条件不满足时,采用 UTF-16 Character Encoding 来保存,也就是每个字符都用 2 个或者 4 个 byte 来保存。
Unicode 是 Coded Character Set,将几乎所有的人类文字映射到 code point 符号,通常格式为 U+xxxx,xxxx 为 16 进制整数,表达范围为 U+0000~U+10FFFF。code point 符号是文字的规范化标记,但是实际保存时肯定还是要保存为字节数组的。这些不同的保存方式就是 Character Encoding,比如 UTF-8,还有 Java String 内部采用的 UTF-16。
UTF-16 是一种将 Unicode code point 表达成字符数组的编码方式,对于 U+0000~U+FFFF,直接按照 2 个字节保存(细分的话还有大端字节序和小端字节序的区别);对于 U+10000~U+10FFFF,会先转化为一对 U+D800~U+DFFF 范围内的 code point(surrogate pair),再将这两个 code point 按照前面的规则保存。之所以选择这个范围,是因为这个 Unicode 区间还没有被分配有效的字符,因此可以和前面的规则区分。
“中文”这两个汉字的 Unicode code point 非别为 U+4E2d、U+6587,大于 0xFF,所以保存 byte 长度为 4;"abc中文" 中存在不满足条件的字符,所以全部用 UTF-16 保存,它们都是 2 个 byte 的,所以长度为 10。
“☺” 的 Unicode code point 为 U+1F60A,根据 UTF-16 规范,U+10000~U+10FFFF 需要转化为 surrogate pair 之后再保存成 byte, 转换后为 U+D83D、U+DE0A,因此 "abc" 的字节长度为 10。
toCharArray()
Java 中 char 的大小为 2 个字节,刚好可以表示一个 U+0000~U+FFFF 的 Unicode 符号。
Latin1 编码时,char 数组为 byte 数组的填充,高字节为 0;UTF-16 编码时,相当于转化过 surrogate pair 后的 Unicode 编码数组,其中 0xD800~0xDFFF 范围内的为 surrogate 字符。
“abc” 时为 Latin1 编码,所以 char 数组大小等于 bytes 数组;“abc中文” 时为 UTF-16 编码,所以 char 数组大小等于 bytes 数组的一半。
codePointCount()
toCharArray 方法将转化后的 surrogate pair 也算在内,因此实际长度可能大于字符长度。而 codePointCount 就能去除 surrogate pair 的影响,返回初始的字符长度,它会将连续两个 surrogate pair 只计数一次。
String.length
该方法就是 toCharArray 数组的长度,受到 surrogate pair 的影响,可能大于字符长度。
str.getBytes().length
String 内部是通过 UTF-16 编码保存的字节数组,当通过 getBytes 方法返回时,是需要指定 Encoding 的,默认采用 UTF-8,因此会将 UTF-16 的字节数组转化为 UTF-8 的字节数组,每个 Unicode 符号在 UTF-8 编码后长度为 1~4 字节。
System.out.println("abc".getBytes(UTF_8).length); // 3
System.out.println("中".getBytes(UTF_8).length); // 3
System.out.println("文".getBytes(UTF_8).length); // 3
System.out.println("".getBytes(UTF_8).length); // 4