JAVAObject中的hashCode()代码示例解析
本篇文章小编给大家分享一下JAVAObject中的hashCode()代码示例解析,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
Object中的hashCode()
hashCode方法用来返回对象的哈希值,提供该方法是为了支持哈希表,例如HashMap,HashTable等,在Object类中的代码如下:
public native int hashCode();
这是一个native声明的本地方法,返回一个int型的整数。由于在Object中,因此每个对象都有一个默认的哈希值。
在openjdk8根路径/hotspot/src/share/vm/runtime路径下的synchronizer.cpp文件中,有生成哈希值的代码:
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0 ;
if (hashCode == 0) {
// 返回随机数
value = os::random() ;
} else
if (hashCode == 1) {
//用对象的内存地址根据某种算法进行计算
intptr_t addrBits = cast_from_oop(obj) >> 3 ;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;
} else
if (hashCode == 2) {
// 始终返回1,用于测试
value = 1 ;
} else
if (hashCode == 3) {
//从0开始计算哈希值
value = ++GVars.hcSequence ;
} else
if (hashCode == 4) {
//输出对象的内存地址
value = cast_from_oop(obj) ;
} else {
// 默认的hashCode生成算法,利用xor-shift算法产生伪随机数
unsigned t = Self->_hashStateX ;
t ^= (t << 11) ;
Self->_hashStateX = Self->_hashStateY ;
Self->_hashStateY = Self->_hashStateZ ;
Self->_hashStateZ = Self->_hashStateW ;
unsigned v = Self->_hashStateW ;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;
Self->_hashStateW = v ;
value = v ;
}
value &= markOopDesc::hash_mask;
if (value == 0) value = 0xBAD ;
assert (value != markOopDesc::no_hash, "invariant") ;
TEVENT (hashCode: GENERATE) ;
return value;
}
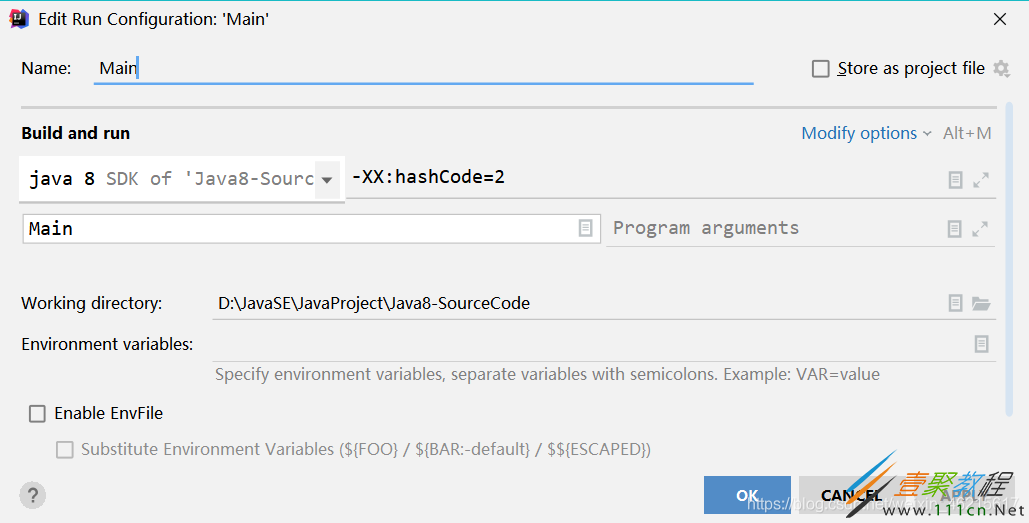
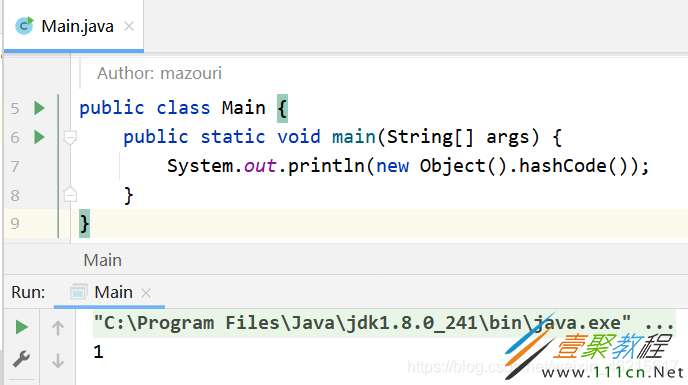
源码中的hashCode其实是JVM启动的一个参数,每一个分支对应一个生成策略,通过-XX:hashCode可以切换hashCode的生成策略。
下面验证第2种生成策略,用软件idea输入参数-XX:hashCode=2,可以看到输出结果正是1,从而进一步验证了上面的源码。
hashCode()和equals()
hashCode()和equals()用来标识对象,两个方法协同工作用来判断两个对象是否相等。对象通过调用 Object.hashCode()生成哈希值,由于不可避免地会存在哈希值冲突的情况 因此hashCode 相同时 还需要再调用 equals 进行一次值的比较,但是若hashCode不同,将直接判定两个对象不同,跳过 equals ,这加快了冲突处理效率。 Object 类定义中对 hashCode和 equals 要求如下:
如果两个对象的equals的结果是相等的,则两个对象的 hashCode 的返回结果也必须是相同的。
任何时候重写equals,都必须同时重写hashCode。
下面看一个小例子:
import java.util.HashMap;
import java.util.Objects;
/**
* @author mazouri
* @create 2021-08-10 23:59
*/
public class Person {
//用户Id,唯一确定用户
private String id;
private String name;
public Person(String id, String name) {
this.id = id;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
return Objects.equals(id, person.id) && Objects.equals(name, person.name);
}
public static void main(String[] args) {
HashMap map = new HashMap<>();
//key:Person类型 value:Integer类型
map.put(new Person("1","张三"),100);
System.out.println(map.get(new Person("1", "张三")));
}
}
我们将Person类的实例作为key,value为这个对象的考试成绩。我们期望通过map.get(new Person("1", "张三"))获取该对象的考试成绩,但上面代码的输出结果为null。原因就在于Person类中没有覆盖hashCode方法,从而导致两个相等的实例具有不同的哈希值。HashMap中get()的核心代码如下
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return first;
if条件表达式中的e.hash == hash是先决条件,只有相等才会执行&&后面的代码。equals不相等时并不强制要求哈希值相等,但是一个优秀的哈希算法应尽可能让元素均匀分布,降低冲突发生的概率,即在equals不相等时尽量让哈希值也不相等,这样&&或||短路操作一旦生效,会极大提高程序的效率。像上面的例子,因为没有重写hashCode方法,两个对象有两个哈希值,获取对象时可能在别的哈希桶中查找,即使凑巧在一个哈希桶,因为哈希值不一样,也找不到原来那一个对象。
你可以根据你自己的需求设计重写hashCode方法,或者调用JDK提供好的,比如
@Override
public int hashCode() {
return Objects.hash(id, name);
}
这样就能解决问题,但是这个运行速度慢一些,因为它们会引发数组的创建,以便传入数目可变的参数, 如果参数中有基本类型,还需要装箱和拆箱 ,建议只将这类散列函数用于不太注重性能的情况。
重写的hashCode()方法
Java为许多常用的数据类型重写了hashCode()方法,比如String,Integer,Double等。比如在Integer类中哈希值就是其int类型的数据。
public static int hashCode(int value) {
return value;
}