MySQL底层数据结构选用B+树原因
本篇文章小编给大家分享一下MySQL底层数据结构选用B+树原因,文章介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
我们都知道MySQL底层数据结构是选用的B+树,那为什么不用红黑树,或者其他什么数据结构呢?
红黑树是一种自平衡二叉查找树,Java8中的hashmap就用到红黑树来优化它的查询效率,可见,红黑树的查询效率还是比较高的,但是为什么MySQL的底层不用红黑树而用B+数呢?
下图是红黑树依次插入1,2,3,4,5,6之后的情况:
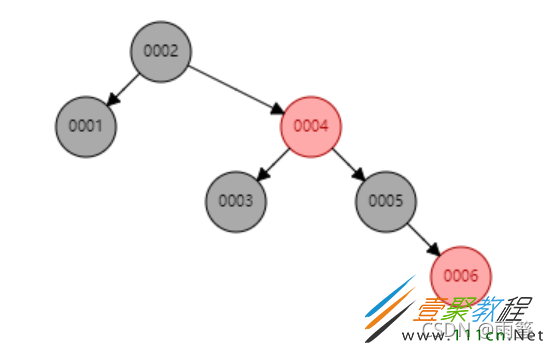
然后再在上面的红黑树中插入7:
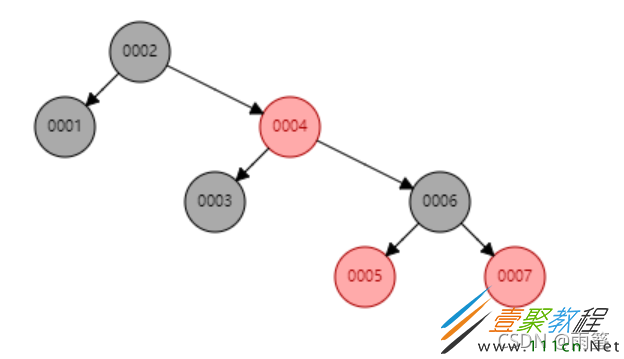
可以看到,尽管红黑树经过了自平衡,数据整体仍然偏向树的右侧,如果继续添加更多数据,添加的数据上百万、千万之后,树的层级将会非常高,查询时每多经过一层,就会多进行一次io,树的层级多了之后查找效率就会很慢。这个时候可能就会有人问了,那为什么不用平衡性更好的AVL树呢?
AVL树在一次插入1,2,3,4,5,6,7之后是这样的:
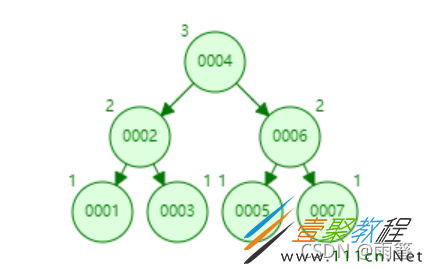
的确变顺眼了很多,树的层数也变少了,可AVL仍然没有解决根本问题,当数据量达到百万、千万之后,树的层数仍然会比较大,先不说AVL树维护平衡所需的代价,单论AVL树的层数就无法达到我们的要求。
那么什么样的数据结构可以让数据量达到百万,千万,甚至更大的体量时,层数仍然很小呢?很显然,想要减少层数,就必须要让每层储存的数据数更多,二叉树不管平衡性再好也只能做到每个节点有两个分叉,每层的数据量从数据结构被限制住了,那么,我们就不能从二叉树中选。所以这个时候B树的优势就体现出来了,B树每个节点可以存储多个元素,每个元素之间可以都可以拥有一个分叉,下图是B树每个节点最多可以存储3个元素的情况:

可以看到树的层级减小到两层,如果说每次每个节点最多可以存储的元素个数足够大,那么就算数据量达到上千万的量级,也可以将树的层级控制在一个可以接受的范围内。
但B树还有一个问题,下图展示的是B树层级达到三层时的情况:
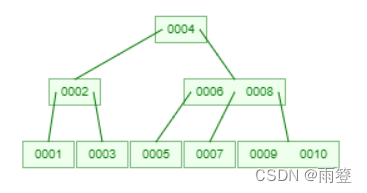
如果现在我需要取出5-10号元素,当我通过层层查询,找到5号元素,然后发现其他元素不在这个节点,还需要通过局部中序遍历查询其他元素,找到7之后还需如此操作找到8,9,10,这又会增加io次数,所以也就有了B+树。
B+树是对B树的优化,主要是从两个地方进行优化的:
第一个优化是在每个叶子节点之间加上了一个双向指针,指向相邻节点,这样就解决了刚才的范围查询问题,范围查询如果跨了多个节点,就可以通过这个双向指针快速找到相邻节点,而不需要通过局部的中序遍历,从而减少了io次数。下图演示的是B+树:
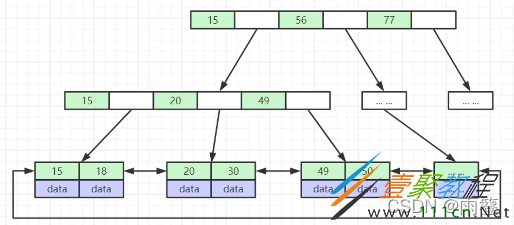
但如果要找的元素不在叶子节点上呢?别担心,B+树的另一个优化就是的叶子节点包含了这颗树的所有元素!B+树的非叶子节点不再保存元素的data数据或者指针了,只是作为冗余的索引构成完整的B+树来方便查询。可以看到上图的15号元素不仅仅存在于非叶子节点中,也存在于叶子节点中。这样的设计虽然带来了很多冗余的索引,但是却让范围查询时不再需要向上查找非叶子节点了,而且每一层可以保存的索引数量变多了,让数据库每次io可以查询到更多的索引元素,毕竟在正常情况下,数据占的空间比索引占的空间要大很多。(需要注意的是,InnoDB和MyISAM引擎虽然都是用的B+树,但InnoDB的聚簇索引和数据是保存在一起的,而MyISAM是将聚簇索引和相应数据的指针保存在一起的,索引和数据是分开的。MyISAM引擎下的B+树也只有叶子节点才保存数据的指针)
由上面的分析我们可以知道,选用B+树作为MySQL的底层是为了减少io次数,那我们为什么不直接极端一点,使用hash来保存数据或者索引呢?其实MySQL确实支持hash类型的索引。

但是hash索引一般都不用,主要是因为hash索引的储存的是hash码,储存的顺序与索引列的值大小无关,所以只有在进行精确查找时hash索引才能生效,范围查询时会进行全表扫描。同时,如果表中的数据量非常大的话,发生hash碰撞的次数会增多,单个查找的效率不一定比B+树高。
简单总结一下,B+树相比其他树来说,每个节点可以存储更多元素,可以大大减少查询时需要的io次数,非叶子节点不存储数据或指针的设计可以提高每个节点存储元素的数量,叶子节点具有的双向指针可以提高范围查询的效率。