分布式数据存储系统的三要素一览
本篇文章小编给大家分享一下分布式数据存储系统的三要素一览,文章介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
前言
CAP 理论指出,在分布式系统中,不能同时满足一致性、可用性和分区容错性,指导了分布式数据存储系统的设计。
随着数据量和访问量的增加,单机性能已经不能满足用户需求,分布式集群存储成为一种常用方式。把数据分布在多台存储节点上,可以为大规模应用提供大容量、高性能、高可用、 高扩展的存储服务。而分布式存储系统就是其具体实现。
分布式存储系统的关键三要素:顾客、导购与货架。
什么是分布式数据存储系统?
分布式存储系统的核心逻辑:将用户需要存储的数据根据某种规则存储到不同的机器上,当用户想要获取指定数据时,再按照规则到存储数据的机器里获取。
如下图所示,当用户(即应用程序)想要访问数据 D,分布式操作引擎通过一些映射方式,比如 Hash、一致性 Hash、数据范围分类等,将用户引导至数据 D 所属的存储节点获取数据。

获取数据的整个过程与商店购物的过程类似,顾客到商店购物时,导购会根据顾客想要购买的商品引导顾客到相应的货架,然后顾客从这 个货架上获取要购买的商品,完成购物。这里的顾客就是图中的应用程序,导购就相当于分布式操作引擎,它会按照一定的规则找到相应的货架,货架就是存储数据的不同机器节点。
这个过程就是分布式存储系统中获取数据的通用流程,顾客、导购和货架组成了分布式存储系统的三要素,分别对应着分布式领域中的数据生产者 / 消费者、数据索引和数据存储。
分布式数据存储系统三要素
顾客就是数据的生产者和消费者,顾客代表两类角色,生产者会生产数据(比如, 商店购物例子中的供货商就属于生产类顾客),将数据存储到分布式数据存储系统中,消费者是从分布式数据存储系统中获取数据进行消费(比如,商店购物例子中购买商品的用户就属于消费类顾客);导购就是数据索引,将访问数据的请求转发到数据所在的存储节点;货架就是存储设备,用于存储数据。
顾客:生产和消费数据
顾客相当于分布式存储系统中的应用程序,而数据是应用程序的原动力。根据数据的产生和使用,顾客分为生产者和消费者两种类型。生产者负责给存储系统添加数据,而消费者则可以使用系统中存储的数据。
就像是火车票存储系统,铁路局就相当于生产者类型的顾客,而乘客就相当于消费者类型的顾客。铁路局将各个线路的火车票信息发布到订票网站的后台数据库中,乘客通过订票网站访问数据库,来进行查询余票、订票、退票等操作。

生产者和消费者生产和消费的数据通常是多种多样的,不同应用场景中数据的类型、格式等都不一样。根据数据的特征,这些不同的数据通常被划分为三类:结构化数据、半结构化数据和非结构化数据:
结构化数据:指关系模型数据,其特征是数据关联较大、格式固定。火车票信息比如起点站、终点站、车次、票价等,就是一种结构化数据。结构化数据具有格式固定的特征,因此一般采用分布式关系数据库进行存储和查询。半结构化数据:指非关系模型的,有基本固定结构模式的数据,其特征是数据之间关系比较简单。比如 HTML 文档,使用标签书写内容。半结构化数据大多可以采用键值对形式来表示,比如 HTML 文档可以将标签设置为 key,标签对应的内容可以设置为 value,因此一般采用分布式键值系统进行存储和使用。非结构化数据:指没有固定模式的数据,其特征是数据之间关联不大。比如文本数据就是一种非结构化数据。这种数据可以存储到文档中,通过 ElasticSearch(一个分布式全文搜索引擎)等进行检索。
导购:确定数据位置
导购是分布式存储系统必不可少的要素,如果没有导购, 顾客就需要逐个货架去寻找自己想要的商品。如果去订票网站订火车票,按照自己的需求点击查询车票后,系统会逐个扫描分布式存储系统中每台机器的数据,寻找你想要购买的火车票。如果系统中存储的数据不多,响应时间也不会太长,毕竟计算机的速度还是很快的;但如果数据分布在几千台甚至上万台机器中,系统逐个机器扫描后再给你响应,严重影响购票体验。
因此在分布式存储系统中,必须有相应的数据导购,否则系统响应会很慢,效率很低。为解决这个问题,数据分片技术就走入了分布式存储系统中。
数据分片技术:指分布式存储系统按照一定的规则将数据存储到相对应的存储节点中,或者到相对应的存储节点中获取想要的数据,优点:
降低单个存储节点的存储和访问压力;通过规定好的规则快速找到数据所在的存储节点,从而大大降低搜索延迟,提高用户体验。
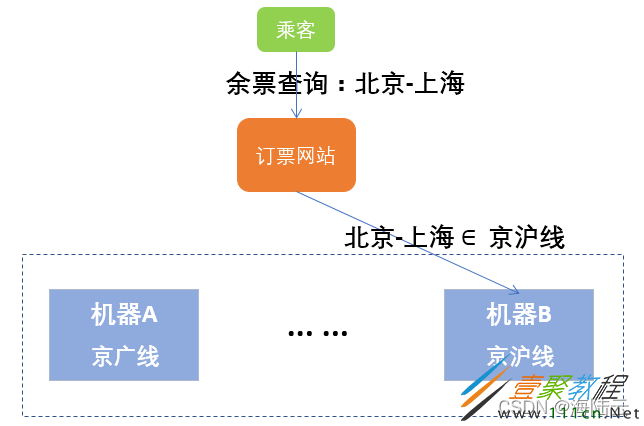
当铁路局发布各个线路的火车票信息时,会按照一定规则存储到相应的机器中, 比如北京到上海的火车票存储到机器 A 中,西安到重庆的火车票存储到机器 B 中。当乘客查询火车票时,系统就可以根据查询条件迅速定位到相对应的存储机器,然后将数据返回给用户,响应时间就大大缩短了。如图所示,当查询北京 - 上海的火车票相关信息时,可以与机器 A 进行数据交互。

例子中按照数据起点、终点的方式划分数据,将数据分为几部分存储到不同的机器节点中,就是数据分片技术的一种。当查询数据时,系统可以根据查询条件迅速找到对应的存储节点,从而实现快速响应。 还有其他很多数据分片的方案。比如,按照数据范围,采用哈希映射、一致性哈希环等对数据划分。
针对数据范围的数据分片方案:按照某种规则划分数据范围,然后将在这个范围内的数据归属到一个集合中。这就好比数学中通常讲的整数区间,比如 1~1000 的整数,[1,100] 的整数属于一个子集、[101,1000] 的整数属于另一个子集。
对于前面讲的火车票的案例,按照数据范围分片的话,可以将属于某条线的所有火车票数据划分到一个子集或分区进行存储,比如机器 A 存储京广线的火车票数据,机器 B 存储京沪线的火车票数据。数据范围的方案是按照范围或区间进行存储或查询。
如图所示,当用户查询北京 - 上海的火车票相关信息时,首先判断查询条件属于哪个范围,由于北京 - 上海的火车线路属于京沪线,因此系统按照规则将查询请求转到存取京沪线火车票数据的机器 B,然后由机器 B 进行处理并给用户返回响应结果。
为了提高分布式系统的可用性与可靠性,除了通过数据分片减少单个节点的压力外,数据复制也是一个非常重要的方法。数据复制是将数据进行备份,以使得多个节点存储该数据。
数据复制和数据分片技术的区别:
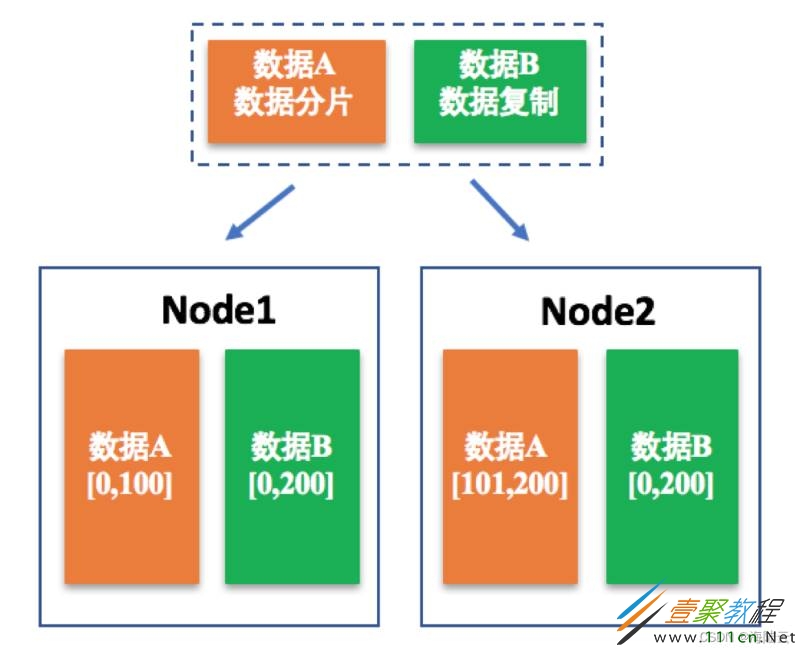
数据 A 被拆分为两部分存储在两个节点 Node1 和 Node2 上,属于数据分片;数据 B 同一份完整的数据在两个节点中均有存储,就属于数据复制。
在实际的分布式存储系统中,数据分片和数据复制通常是共存的:
数据通过分片方式存储到不同的节点上,以减少单节点的性能瓶颈问题;而数据的存储通常用主备方式保证可靠性,对每个节点上存储的分片数据,采用主备方式存储,以保证数据的可靠性。主备节点上数据的一致,是通过数据复制技术实现的。
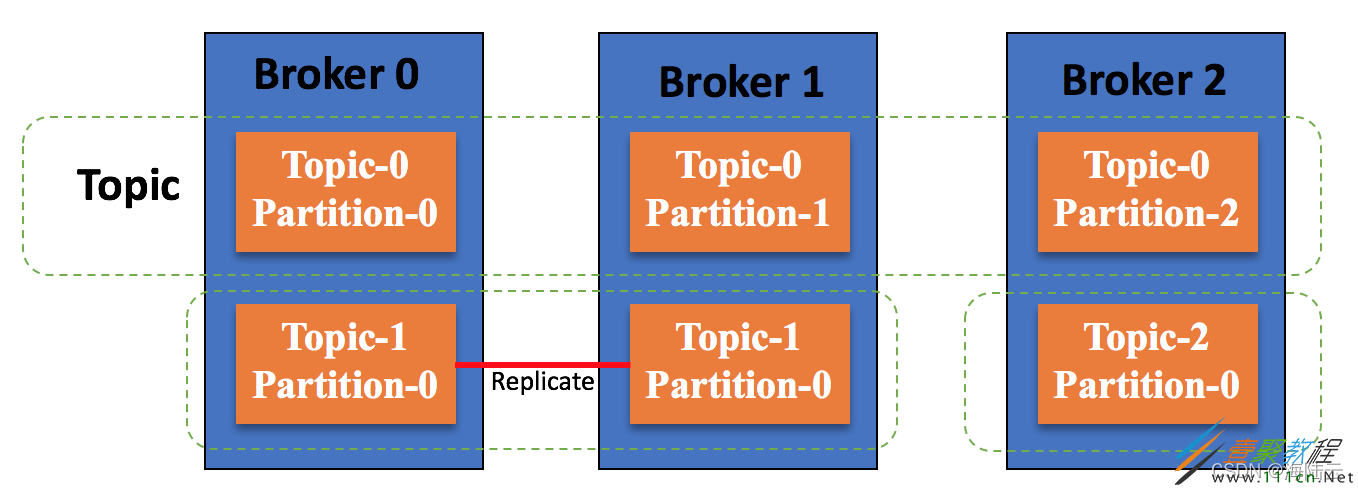
Kafka 集群消息存储架构图,消息数据以 Partition(分区)进行存储,一个 Topic(主题)可以由多个 Partition 进行存储,Partition 可以分布到多个 Broker 中;同时,Kafka 还提供了 Partition 副本机制(对分区存储的信息进行备份,比如 Broker 1 中的 Topic-1 Partion-0 是对 Broker 0 上的 Topic-1 Partition-0 进行的备份),从而保证了消息存储的可靠性。
货架:存储数据
货架是用来存储数据的,因为数据是由顾客产生和消费的,因此货架存储的数据类型与顾客产生和消费的数据类型是一致的,即包括结构化数据、半结构化数据和非结构化数据。
针对这三种不同的数据类型,存储“货架”划分为三种:
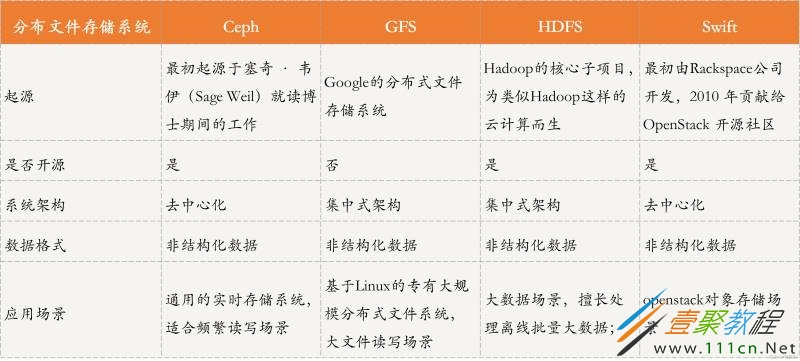
分布式数据库:通过表格来存储结构化数据,方便查找。常用的分布式数据库有 MySQL Sharding、Microsoft SQL Azure、Google Spanner、Alibaba OceanBase 等。分布式键值系统:通过键值对来存储半结构化数据。常用的分布式键值系统有 Redis、 Memcache 等,可用作缓存系统。分布式存储系统:通过文件、块、对象等来存储非结构化数据。常见的分布式存储系统 有 Ceph、GFS、HDFS、Swift 等。
对存储介质的选择,本质是选择将数据存储在磁盘还是内存(缓存) 上:
磁盘存储量大,但 IO 开销大,访问速度较低,常用于存储不经常使用的数据。比如,电商系统中,排名比较靠后或购买量比较少、甚至无人购买的商品信息,通常就存储在磁盘上。内存容量小,访问速度快,因此常用于存储需要经常访问的数据。比如,电商系统中, 购买量比较多或排名比较靠前的商品信息,通常就存储在内存中。
知识扩展:业界主流的分布式数据存储系统有哪些?
货架针对结构化数据、半结构化数据和非结构化数据,分别对应不同的“货架”,即分布式数据库、分布式键值系统和分布式文件系统进行存储。
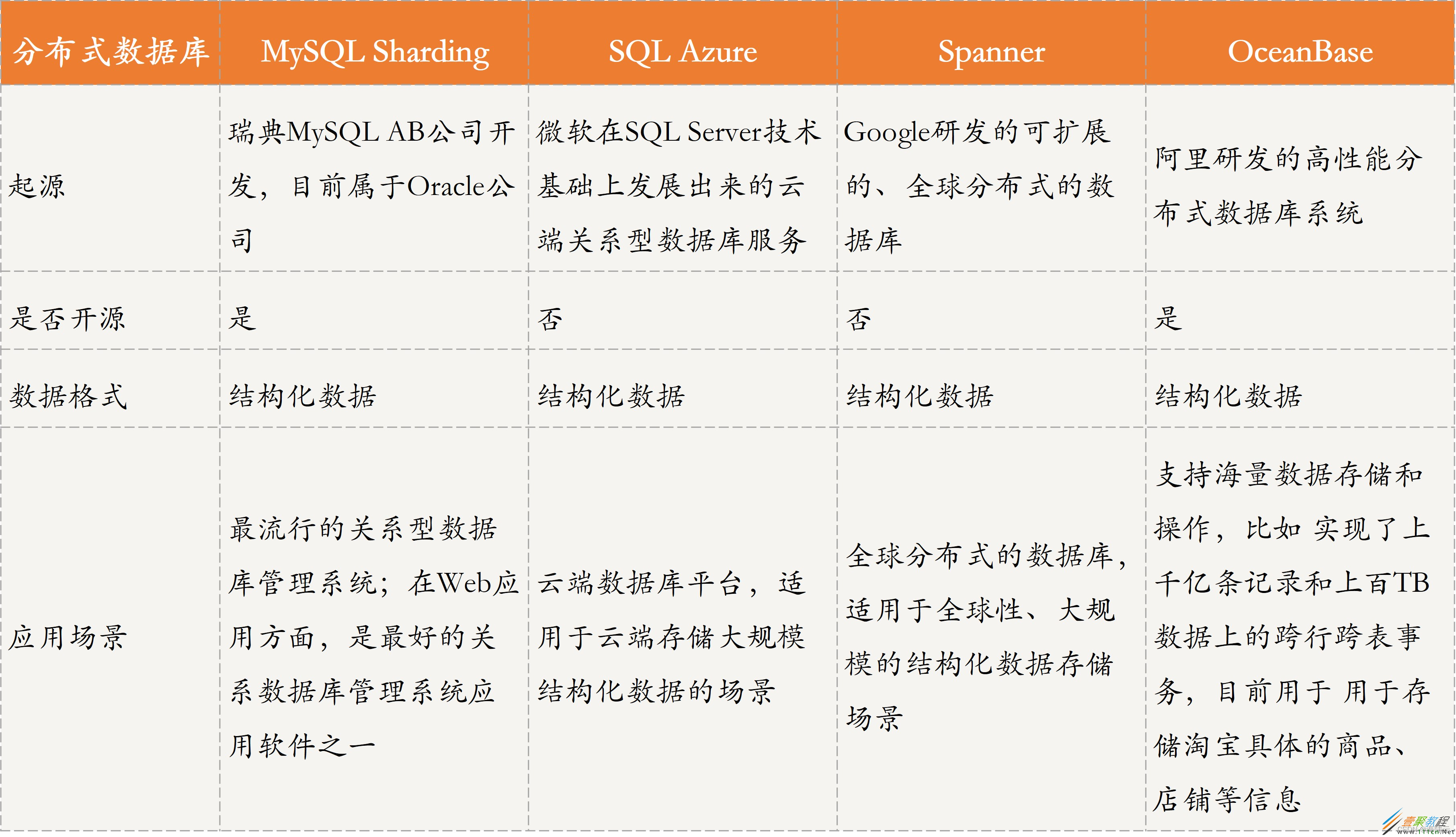
主流的分布式数据库,主要包括 MySQL Sharding、SQL Azure、 Spanner、OceanBase 等。
主流的分布式存储系统,主要包括 Ceph、GFS、HDFS 和 Swift 等。
总结
分布式数据存储系统的三要素,即顾客、导购和货架,对应到分布式领域的术语就是数据生产者 / 消费者、数据索引和数据存储。
顾客包括产生数据的顾客和消费数据的顾客两类;导购是数据索引引擎,包括数据存储时确定数据位置,以及获取数据时确定数据所在位置;货架负责数据存储,包括磁盘、缓存等存储介质等。
不同应用场景中,顾客产生的数据类型、格式等通常都不一样。根据数据的特征,这些不同的数据可以被划分为三类:结构化数据、半结构化数据和非结构化数据。与之相对应的,货架也就是数据存储系统,也包括三类:分布式数据库、分布式键值系统和分布式文件系统。
