一次SQL查重及去重代码实例
本篇文章小编给大家分享一下一次SQL查重及去重代码实例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
1.distinct
题目:现在运营需要查看用户来自于哪些学校,请从用户信息表中取出学校的去重数据
示例:user_profile
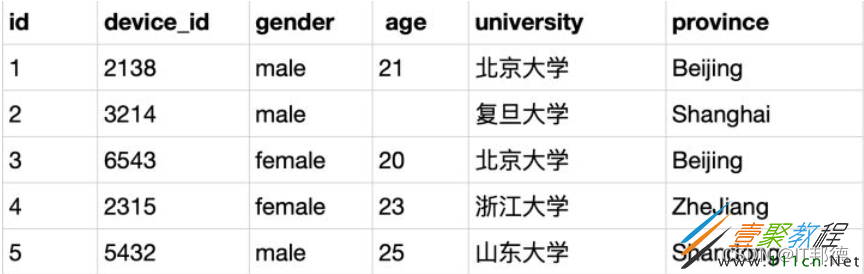
mysql>SELECT DISTINCT university FROM user_profile;
根据示例,查询返回以下结果

小贴士:
SQL中关键词distinct去重:
英语中distinct 代表独一无二的意思,
他在SQL表示去重的意思:比如本题中university这一列出现了两次北京大学,
使用distinct进行去重查询后,则北京大学只出现一次。
distinct 通常效率较低
distinct 使用中,放在 select 后边,对后面所有的字段的值统一进行去重
拓展:
题目:现在运营需要查看用户的总数
select count(distinct university) from user_profile;
2.group by
举个栗子,现有这样一张表 task

备注:
task_id: 任务id;
order_id: 订单id;
start_time: 开始时间
注意:一个任务对应多条订单
题目:列出任务总数
根据示例,查询方法如下:
第1步:列出 task_id 的所有唯一值(去重后的记录,null也是值)
select task_id from Task group by task_id;
第二步: 任务总数
select count(task_id) task_num from (select task_id from Task group by task_id) tmp;
3.row_number 窗口函数
举个栗子,现有这样一张表 task
备注:
task_id: 任务id;
order_id: 订单id;
start_time: 开始时间
注意:一个任务对应多条订单
题目:查询整个表重复的数据
根据示例,查询方法如下:
– 在支持窗口函数的 sql 中使用
select count(case when rn=1 then task_id else null end) task_num from (select task_id , row_number() over (partition by task_id order by start_time) rn from Task) tmp;
小贴士:
MySQL8.0 中可以利用 ROW_NUMBER(),DENSE_RANK(),RANK() 三个窗口函数来实现排序
需要注意的一点是 as 后的别名,千万不要与前面的函数名重名,否则会报错
下面给出这三种函数实现排名的案例:
–三条语句对于上面三种排名
select xuehao,score, ROW_NUMBER() OVER(order by score desc) as row_r from scores_tb; select xuehao,score, DENSE_RANK() OVER(order by score desc) as dense_r from scores_tb; select xuehao,score, RANK() over(order by score desc) as r from scores_tb;
– 一条语句也可以查询出不同排名
SELECT xuehao,score, ROW_NUMBER() OVER w AS ‘row_r', DENSE_RANK() OVER w AS ‘dense_r', RANK() OVER w AS ‘r' FROM scores_tb WINDOW w AS (ORDER BY score desc);
4.删除重复数据
创建测试数据
我们创建一个人员信息表并在里面插入一些重复的数据
CREATE TABLE Person( id int auto_increment primary key comment ‘主键', Name VARCHAR(20) NULL, Age INT NULL, Address VARCHAR(20) NULL, Sex CHAR(2) NULL );
INSERT INTO Person(ID,Name,Age,Address,Sex) VALUES ( 1, ‘张三', 18, ‘北京路18号', ‘男' ), ( 2, ‘李四', 19, ‘北京路29号', ‘男' ), ( 3, ‘王五', 19, ‘南京路11号', ‘女' ), ( 4, ‘张三', 18, ‘北京路18号', ‘男' ), ( 5, ‘李四', 19, ‘北京路29号', ‘男' ), ( 6, ‘张三', 18, ‘北京路18号', ‘男' ), ( 7, ‘王五', 19, ‘南京路11号', ‘女' ), ( 8, ‘马六', 18, ‘南京路19号', ‘女' );
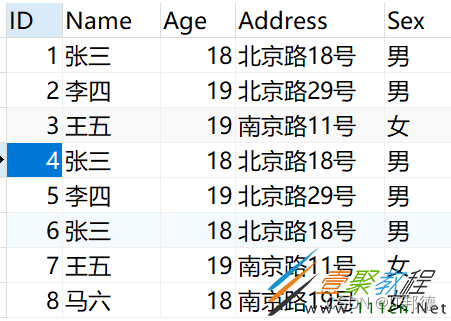
题目:数据库中存在重复记录,删除保留其中一条
我们发现除了自增长ID不同以为,有几条其他字段都重复的数据出现
第一步:找出重复的数据
mysql>SELECT MAX(ID) ID, Name,Age,Address,Sex FROM Person GROUP BY Name,Age,Address,Sex HAVING COUNT(1)>1

小贴士:
HAVING将分组后统计出来的数量大于1的数据行,就是我们要找的重复数据
上面用Max函数或者Min函数均可,只是为了保证取出来的数据的唯一性。
第二步:删除重复的数据
其实我们数据库中最后要保留的结果就是第二步中查询出来的数据,
我们把其他的数据删除即可。
怎么删除呢?我们使用ID来排除。
DELETE FROM Person WHERE EXISTS ( SELECT * FROM ( SELECT MAX(ID) ID, Name,Age,Address,Sex FROM Person GROUP BY Name,Age,Address,Sex HAVING COUNT(1)>1) T WHERE Person.Name=T.Name AND Person.Age=T.Age AND Person.Address=T.Address AND Person.Sex=T.Sex AND Person.ID
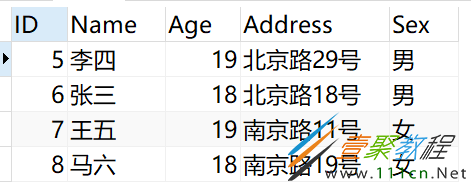
执行完后重新查询Person表结果如下
马六因为只有一条记录,所以没有参与去重,直接显示。