Python全角与半角之间相互转换代码方法
本篇文章小编给大家分享一下Python全角与半角之间相互转换代码方法,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
1.应用领域:
全角和半角的转换通常用在自然语言处理过程中,由于全角和半角的不一致会导致信息抽取不一致,在使用语料训练语言模型会导致模型的效果不准确,所以需要统一。
2.全角半角转换概述
全角字符unicode编码范围从65281~65374 (对应的十六进制范围是: 0xFF01 ~ 0xFF5E)
半角字符unicode编码范围从33~126 (对应的十六进制范围从 0x21~ 0x7E)
空格比较特殊,全角为12288(0x3000),半角为 32 (0x20)
除空格外, 全角/半角按unicode编码排序在顺序上是对应的(半角 +65248 = 全角 or 半角 + 0x7e= 全角 )
所以可以直接通过用±法来处理非空格数据,对空格单独处理
3.请注意:
中文文字永远是全角,只有英文字母、数字键、符号键才有全角半角的概念。
一个字母或数字占一个汉字的位置叫全角,占半个汉字的位置叫半角。
引号在中英文、全半角情况下是不同的
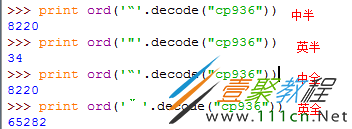
4.应用到的库函数
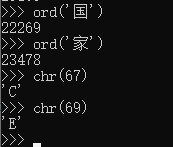
chr()函数用一个范围在range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
unichr()跟它一样,只不过返回的是Unicode字符。
ord()函数是chr()函数(对于8位的ASCII字符串)或unichr()函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的ASCII数值,或者Unicode数值。
示例:
5.全角转半角:
def strQ2B(ustring):
rstring = ""
for uchar in ustring:
inside_code = ord(uchar)
if inside_code == 12288: # 全角空格直接转换
inside_code = 32
elif 65281 <= inside_code <= 65374: # 全角字符(除空格)根据关系转化
inside_code -= 65248
rstring += chr(inside_code)
return rstring
str11 = strQ2B("电影《2012》讲述了2012年12月21日的世界末日,主人公Jack以及世界各国人民挣扎求生的经历!")
print(str11)
运行结果:
电影《2012》讲述了2012年12月21日的世界末日,主人公Jack以及世界各国人民挣扎求生的经历!
6.半角转成全角:
def strB2Q(ustring):
"""半角转全角"""
rstring = ""
for uchar in ustring:
inside_code = ord(uchar)
if inside_code == 32: # 半角空格直接转化
inside_code = 12288
elif 32 <= inside_code <= 126: # 半角字符(除空格)根据关系转化
inside_code += 65248
rstring += chr(inside_code)
return rstring
str22 = strB2Q("电影《2012》讲述了2012年12月21日的世界末日,主人公Jack以及世界各国人民挣扎求生的经历!")
print(str22)
运行结果:
电影《2012》讲述了2012年12月21日的世界末日,主人公Jack以及世界各国人民挣扎求生的经历!
附:如何通过python转换全角字符串为半角字符串实例
# coding:utf-8
from idna import unichr
def all_to_half(all_string):
"""全角转半角"""
half_string = ""
for char in all_string:
inside_code = ord(char)
if inside_code == 12288: # 全角空格直接转换,全角和半角的空格的Unicode值相差12256
inside_code = 32
elif (inside_code >= 65281 and inside_code <= 65374): # 全角字符(除空格)根据关系转化,除空格外的全角和半角的Unicode值相差65248
inside_code -= 65248
half_string += unichr(inside_code)
return half_string