利用python实现查看溧阳的摄影圈代码示例
作者:袖梨
2022-06-25
本篇文章小编给大家分享一下利用python实现查看溧阳的摄影圈代码示例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
目标站点分析
本次要采集的目标站点分页规则如下:
http://www.*jsly**001.com/thread-htm-fid-45-page-{页码}.html
代码采用多线程 threading 模块+requests 模块+BeautifulSoup 模块编写。
采取规则依据列表页 → 详情页:
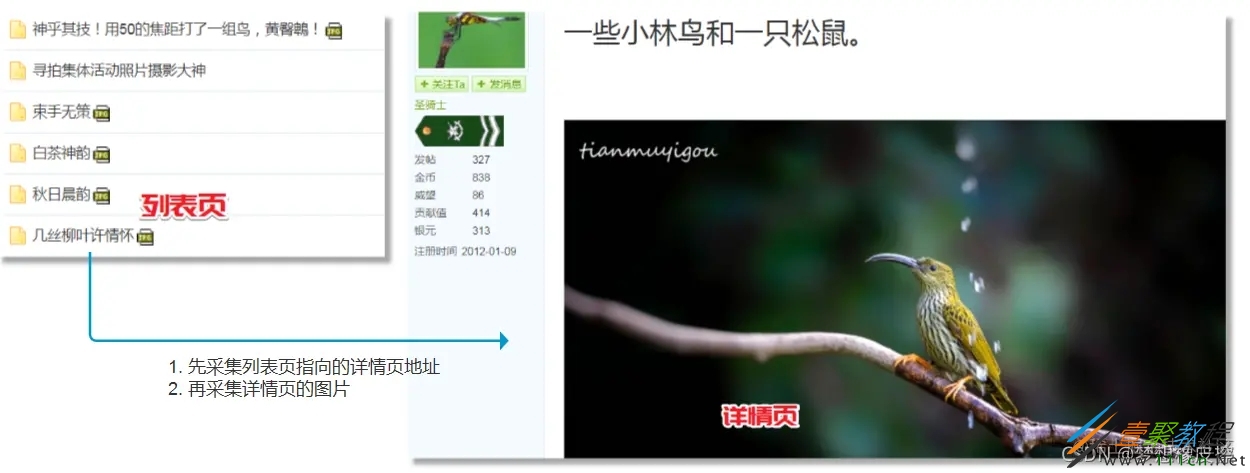
溧阳摄影圈图片采集代码
本案例属于实操案例,先展示完整代码,然后基于注释与重点函数进行说明。
主要实现步骤如下所示:
设置日志输出级别
声明一个 LiYang 类,其继承自 threading.Thread
实例化多线程对象
每个线程都去获取全局资源
调用html解析函数
获取板块主题分割区域,主要为防止获取置顶的主题
使用 lxml 进行解析
解析出标题与数据
解析图片地址
保存图片
import random
import threading
import logging
from bs4 import BeautifulSoup
import requests
import lxml
logging.basicConfig(level=logging.NOTSET) # 设置日志输出级别
# 声明一个 LiYang 类,其继承自 threading.Thread
class LiYangThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self) # 实例化多线程对象
self._headers = self._get_headers() # 随机获取 ua
self._timeout = 5 # 设置超时时间
# 每个线程都去获取全局资源
def run(self):
# while True: # 此处为多线程开启位置
try:
res = requests.get(url="http://www.*js*ly00*1.com/thread-htm-fid-45-page-1.html", headers=self._headers,
timeout=self._timeout) # 测试获取第一页数据
except Exception as e:
logging.error(e)
if res is not None:
html_text = res.text
self._format_html(html_text) # 调用html解析函数
def _format_html(self, html):
# 使用 lxml 进行解析
soup = BeautifulSoup(html, 'lxml')
# 获取板块主题分割区域,主要为防止获取置顶的主题
part_tr = soup.find(attrs={'class': 'bbs_tr4'})
if part_tr is not None:
items = part_tr.find_all_next(attrs={"name": "readlink"}) # 获取详情页地址
else:
items = soup.find_all(attrs={"name": "readlink"})
# 解析出标题与数据
data = [(item.text, f'http://www.j*s*ly0*01.com/{item["href"]}') for item in items]
# 进入标题内页
for name, url in data:
self._get_imgs(name, url)
def _get_imgs(self, name, url):
"""解析图片地址"""
try:
res = requests.get(url=url, headers=self._headers, timeout=self._timeout)
except Exception as e:
logging.error(e)
# 图片提取逻辑
if res is not None:
soup = BeautifulSoup(res.text, 'lxml')
origin_div1 = soup.find(attrs={'class': 'tpc_content'})
origin_div2 = soup.find(attrs={'class': 'imgList'})
content = origin_div2 if origin_div2 else origin_div1
if content is not None:
imgs = content.find_all('img')
# print([img.get("src") for img in imgs])
self._save_img(name, imgs) # 保存图片
def _save_img(self, name, imgs):
"""保存图片"""
for img in imgs:
url = img.get("src")
if url.find('http')
本次案例采用中,BeautifulSoup 模块采用lxml 解析器对 HTML 数据进行解析,后续多采用此解析器,在使用前注意先导入lxml模块。
数据提取部分采用soup.find()与soup.find_all()两个函数进行,代码中还使用了find_parent()函数,用于采集父级标签中的id属性。
# 寻找父标签中的 id 属性
id_ = img.find_parent('span').get("id")
代码运行过程出现 DEBUG 信息,控制logging日志输出级别即可。