Mysql数据库事务的脏读幻读及不可重复读代码解析
本篇文章小编给大家分享一下Mysql数据库事务的脏读幻读及不可重复读代码解析,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
一、什么是数据库事务
数据库事务( transaction)是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务由事务开始与事务结束之间执行的全部数据库操作组成。——百度百科
比如,你有2条sql要执行,如果放到一个事务里,要么2个sql都执行成功,要么都失败。都执行成功了就提交事务,有一个失败了就回滚,不存在一个成功一个失败。
二、事务的ACID原则
这是数据库事务的核心所在。
1. 原子性(Atomicity)
比如现在A有800元,B有200元,A给B转账200元。完成此场景有2步,可以当做在一个事务里:
1- A:800-200=600
2- B:200+200=400
那么,这2个步骤只能都成功,或者都失败。如果一个成功一个失败了,那么有一个人的钱就不对了。原子性就是表示不能只发生其中一个动作。
2. 一致性(Consistency)
针对一个事务操作前与操作后的状态一致。
比如现在A有800元,B有200元,2个人总计是1000元。那么不管这2个人之间怎么转来转去,总和一定还是1000元,钱不会凭空产生或消失。
3. 持久性(Durability)
对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
比如现在A有800元,B有200元,此时A要给B转账200,或有2种情况:
1. 事务还没提交,这时候服务挂了或者断电,那么重启数据库后,数据状态应该为:A有800元,B有200元
2. 事务已经提交,这时候服务挂了或者断电,那么重启数据库后,数据状态应该为:A有600元,B有400元
可以看到,事务一旦提交,就会持久化到数据库里,不会因外界原因导致数据丢失。
4. 隔离性(Isolation)
事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
比如现在有2个事务同时进行,A和C同时在给B转账:
事务一:A有800元,B有200元,A给B转账200元
事务二:C有1000元,B有200元,C给B转账100元
这2个事务不会互相影响。隔离性就是针对多用户同时操作的情况下,排除其他事务对本事务的影响。
三、隔离带来的问题
数据库的事务隔离级别有4个,强度从低到高依次为:
Read uncommitted 、Read committed 、Repeatable read、Serializable,而随着隔离级别的不同,会引发一些其他的问题。
1. 脏读
一个事务读取了另外一个事务未提交的数据,就是脏读。
事务1: A给B转账500,但是事务未提交。
事务2: B查看了账户,发现A转过来500,本来只转300过来就好,发现多转了200,心里美滋滋。。。
事务1: A及时发现多转了200,修改了转300,提交事务。
最终,B再次查看账户的时候发现还是只多了300块,白高兴一场,这种就是脏读。当隔离级别设置为Read uncommitted时可能会出现该情况。
若避开脏读,可以设置隔离级别为Read committed。
2. 不可重复读
一个事务先后读取同一条记录,而事务在两次读取之间该数据被其它事务所修改,则两次读取的数据不同,这种就是不可重复读。
事务1:B去买东西,卡里有500块钱,消费100,还没提交事务。
事务2:B的老婆把B的500块钱转出去了,已提交事务。
事务1:B此时提交事务,支付不了。再次读取发现卡里没钱支付。
当隔离级别设置为Read committed,可以避免脏读,但是可能会造成不可重复读。
若避开不可重复读,可以设置隔离级别为Repeatable read。
3.幻读
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为幻读。
事务1:B的老婆查看B的卡消费记录,目前共消费了500元。
事务2:B此时刚在外面请朋友吃完饭,付款了100,事务已提交。
B的老婆决定把账单打印出来,晚上跟B对账,却发现打印出来的消费为600元。她刚才明明看到是500,怎么是600,难道是幻觉?
Mysql的默认隔离级别为Repeatable read,可以避免不可重复读,但是可能出现幻读的情况。
如果要继续解决幻读,那么可以将隔离级别设置为最高级的Serializable,这时候事务都是按照顺序执行的,脏读、幻读、不可重复度都可以避免,但是性能很差。
四、手动测试下事务的过程
可以在mysql里手动去执行事务提交的过程,辅助理解。现在来模拟一个转账的过程,A给B转账500。
先创造下测试条件,造库、表、数据。
-- 创建库
CREATE DATABASE shop CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 使用库
USE shop;
-- 创建表
CREATE TABLE `account`(
`id` INT(3) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(30) NOT NULL,
`money` DECIMAL(9,2) NOT NULL,
PRIMARY KEY (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
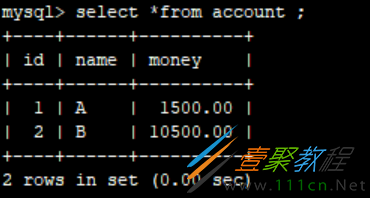
-- 插入数据
INSERT INTO account(`name`,`money`)
VALUES ('A', 2000.00),('B', 10000.00)
上述sql都执行完即可,现在有2条测试数据。
接下来手动执行事务提交的过程。
关闭自动提交
SET autocommit = 0; -- 关闭自动提交,默认是打开
执行sql。
开启一个事务
START TRANSACTION -- 开启一个事务
执行sql。
定义事务里的sql
开启事务后的sql,就是定义在一个事务里了。
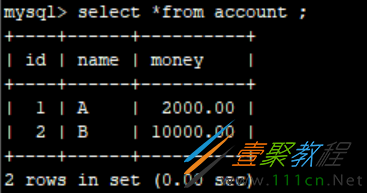
UPDATE account SET money=money - 500 WHERE `name` = 'A' -- A减去500 UPDATE account SET money=money - 500 WHERE `name` = 'B' -- B增加500
执行后,数据变更。A加了500,B少了500。
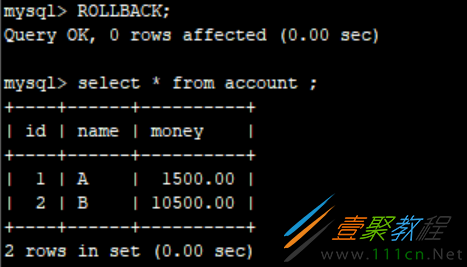
现在我不去提交,进行回滚。
ROLLBACK; -- 回滚
数据变回最开始的样子。
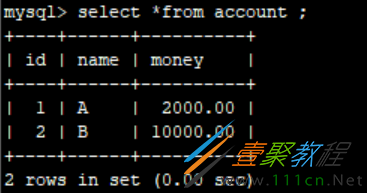
重新执行2条sql,并且提交事务。
UPDATE `shop`.`account` SET `money`=`money` - 500 WHERE `name` = 'A'; -- A减去500 UPDATE `shop`.`account` SET `money`=`money` + 500 WHERE `name` = 'B'; -- B增加500 COMMIT; -- 提交事务
数据修改成功,此时再次执行回滚,数据已经不可逆了。