MySQL子查询与HA5ING/SELECT的结合使用
作者:袖梨
2023-08-16
这篇文章主要介绍了MySQL子查询在HAVING/SELECT字句中使用、及相关子查询和WITH/EXISTS字句的使用,具有一定的参考价值,感兴趣的可以了解一下
前言
本节将为大家带来MySQL子查询在HAVING/SELECT字句中使用、及相关子查询和WITH/EXISTS字句的讲解✨
一、在HAVING/SELECT字句中使用子查询
✨✨HAVING字句
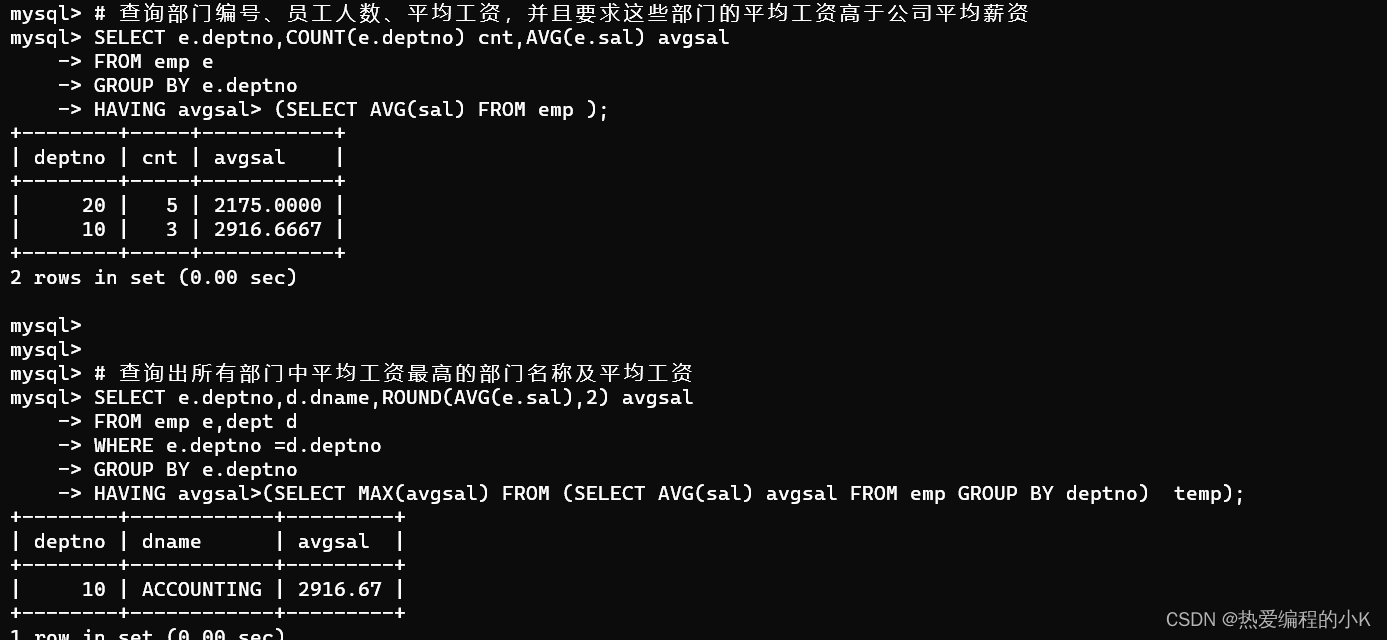
查询部门编号、员工人数、平均工资,并且要求这些部门的平均工资高于公司平均薪资。
SELECT deptno,COUNT(deptno) cnt,AVG(sal) avgsal FROM emp GROUP BY deptnoHAVING avgsal>(SELECT AVG(sal) FROM emp);
查询出所有部门中平均工资最高的部门名称及平均工资
SELECT e.deptno,d.dname,ROUND(AVG(sal),2) avgsalFROM emp e,dept dWHERE e.deptno=d.deptnoGROUP BY e.deptnoHAVING avgsal>( #查询出所有部门平均工资中最高的薪资 SELECT MAX(avgsal) FROM (SELECT AVG(sal) avgsal FROM emp GROUP BY deptno) AS temp)
✨✨SELECT字句
查询出公司每个部门的编号、名称、位置、部门人数、平均工资
#1多表查询SELECT d.deptno,d.dname,d.loc,COUNT(e.deptno),AVG(e.sal)FROM emp e,dept dWHERE e.deptno=d.deptnoGROUP BY e.deptno;#2SELECT d.deptno,d.dname,d.loc,temp.cnt,temp.avgsalFROM dept d,(SELECT deptno,COUNT(deptno) cnt,AVG(sal) avgsal FROM emp GROUP BY deptno) tempWHERE d.deptno=temp.deptno;#3 关联子查询SELECT d.deptno,d.dname,d.loc,(SELECT COUNT(deptno) FROM emp WHERE deptno=d.deptno GROUP BY deptno) cnt,(SELECT AVG(sal) FROM emp WHERE deptno=d.deptno GROUP BY deptno) avgsalFROM dept d;

二、相关子查询
✨如果子查询的执行依赖外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就成为关联子查询。相关子查询按照一行接一行的顺序指针,主查询的每一行都指向一次子查询。

✨查询需求
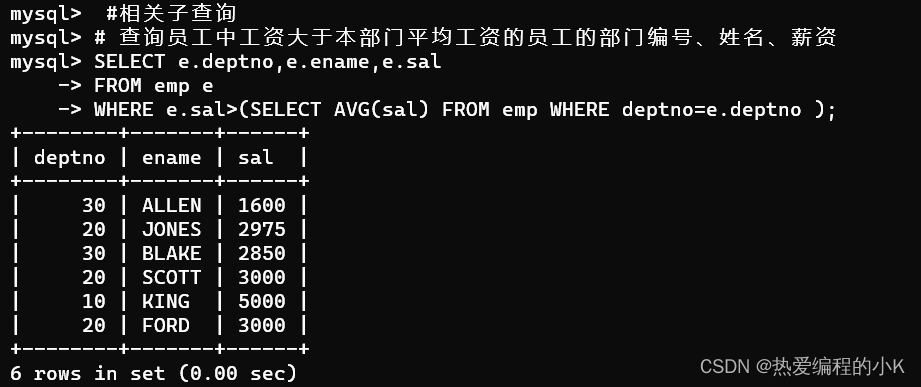
查询员工中工资大于本部门平均工资的员工的部门编号、姓名、薪资
SELECT e.deptno,e.ename,e.salFROM emp eWHERE e.sal>(SELECT AVG(sal) FROM emp WHERE deptno=e.deptno );
三、WITH/EXISTS、NOT EXISTS字句
✨✨WITH字句
查询每个部门的编号、名称、位置、部门平均工资、人数
-- 多表查询SELECT d.deptno,d.dname,d.loc,AVG(e.sal) avgsal ,COUNT(e.deptno) cntFROM dept d,emp eWHERE d.deptno=e.deptnoGROUP BY e.deptno;-- 子查询SELECT d.deptno,d.dname,d.loc,temp.avgsal,temp.cntFROM dept d,(SELECT deptno,AVG(sal) avgsal,COUNT(deptno) cntFROM empGROUP BY deptno)tempWHERE d.deptno=temp.deptno;-- 使用withWITH temp AS(SELECT deptno,AVG(sal) avgsal,COUNT(deptno) cntFROM empGROUP BY deptno)SELECT d.deptno,d.dname,d.loc,temp.avgsal,temp.cntFROM dept d,tempWHERE d.deptno=temp.deptno;
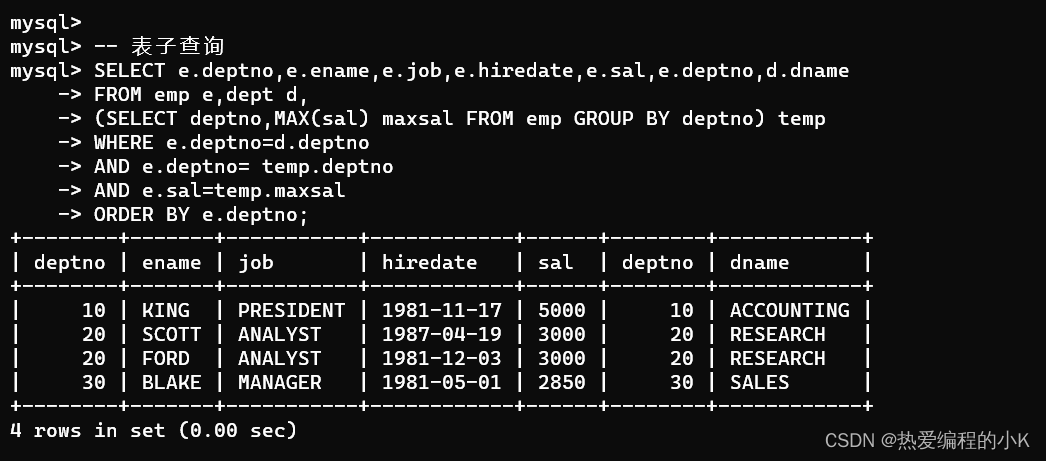
查询每个部门工资最高的员工编号、姓名、职位、雇佣日期、工资、部门编号、部门名称,显示的结果按照部门编号进行排序
-- 相关子查询SELECT e.empno,e.ename,e.job,e.hiredate,e.sal,e.deptno,d.dnameFROM emp e,dept dWHERE e.deptno=d.deptnoAND e.sal=(SELECT MAX(sal) FROM emp WHERE deptno=e.deptno)ORDER BY e.deptno;-- 表子查询SELECT e.empno,e.ename,e.job,e.hiredate,e.sal,e.deptno,d.dnameFROM emp e,dept d,(SELECT deptno,MAX(sal) maxsal FROM emp GROUP BY deptno) tempWHERE e.deptno=d.deptnoAND e.sal=temp.maxsalAND e.deptno = temp.deptnoORDER BY e.deptno;

✨✨EXISTS/NOT EXISTS字句
在SQL中提供了一个exixts结构用于判断子查询是否有数据返回。如果子查询中有数据返回,exists结构返回true,否则返回false。
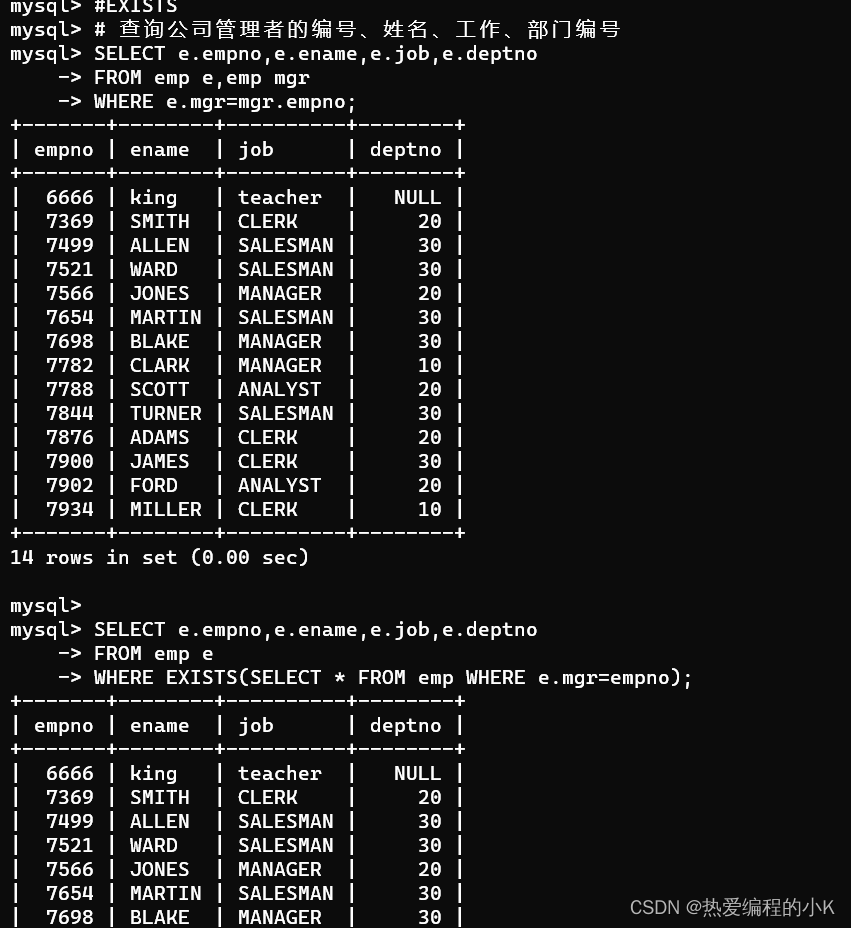
查询公司管理者的编号、姓名、工作、部门编号
-- 多表查询SELECT DISTINCT e.empno,e.ename,e.job,e.deptnoFROM emp e JOIN emp mgrON e.empno=mgr.mgr;-- 使用EXISTSSELECT e.empno,e.ename,e.job,e.deptnoFROM emp eWHERE EXISTS (SELECT * FROM emp WHERE e.empno=mgr);
查询部门表中,不存在于员工表中的部门信息
-- 多表查询SELECT e.deptno,d.deptno,d.dname,d.locFROM emp e RIGHT JOIN dept dON e.deptno=d.deptnoWHERE e.deptno IS NULL;-- 使用EXISTSSELECT d.deptno,d.dname,d.locFROM dept dWHERE NOT EXISTS (SELECT deptno FROM emp WHERE deptno=d.deptno);

四、总结
✨✨ 子查询允许结构化的查询,这样就可以把一个查询语句的每个部分隔开。✨✨子查询提供了另一种方法来执行有些需要复杂的join和union来实现的操作。✨✨在许多人看来,子查询可读性较高。 而实际上,这也是子查询的由来。
到此这篇关于MySQL子查询与HAVING/SELECT的结合使用的文章就介绍到这了,更多相关MySQL子查询与HAVING/SELECT内容请搜索一聚教程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持一聚教程网!