Sql效能优化总结与sql语句优化篇
今晚继续进行Sql效能问题的分享,今天主要是一些具体的sql优化方法和思路分享,若看过后你也有其他想法,欢迎一起探讨,好了,进入今天的主题。
针对性地对一些耗资源严重的具体应用进行优化
出现效能问题时,首先要做的是什么?这个问题我问过不少同事,有人说凭经验对出问题的sql进行优化,如我们一般说的要合理使用索引,尽量不要使用前面带*号的Like语句,不要再比较操作符前边进行计算或使用函数等等,这些道路都是对的,但经验有时候不一定能解决问题。问题出现时,首先要做的是确定问题点是什么,只有正确的找到问题后才能有针对性的解决问题。下面简单介绍我们一般从哪些角度入手,来确定问题所在。
1.首先从业务上理解该处功能,理解用户的真正意图,用户真正关注的是什么,想要的是什么数据,是否有变通简洁的方法达到用户要求。而非使用复杂sql查询。其实有些时候进行变通的修改,同样能达到目的,但是采用的sql语句已经极大地简化了。这是解决效能问题的优先要考虑的。
2.对固定的sql进行优化时,一定要关注查询相关的数据量,关注数据量的大小,有些时候用户进行一个查询,若没有处理好查询条件的话,返回的记录集合太大,这对用户来说,其实意义不大,关键是这样必然会导致较多的磁盘IO,效能问题是必然的。除非是用户真的需要这么多数据,但事实证明,多数都不是的,所以着眼点是怎样限制返回的记录集的大小或查询中使用的临时中间数据集合的大小。这样才能使你的优化达到效果,起到作用。
下面简单介绍几种常用的检查问题sql的方法。
当然其中是有些技巧的,如:
- 使用 set statistics io on 检查实际的磁盘IO信息,物理读、逻辑读等信息,这个是一个简单有效的参考数据,在笔者以往的经验中,也是主要的参考数据。
在查询分析器中贴出问题sql,使用set statistics io 为on,也可以在空白处点击右键,选择<查询选项>,

选择<高级>
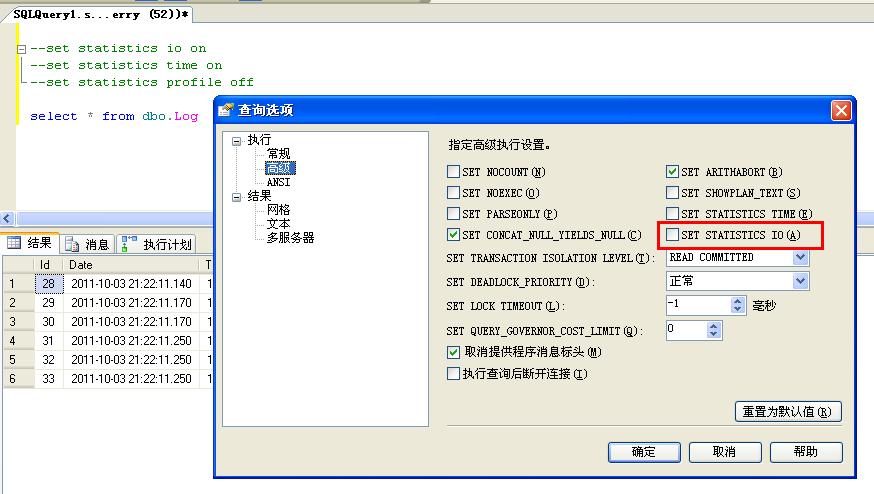
勾选Set Statistics Io 。
运行查询,除了得到结果集合以外,还可以得到本次查询相关的IO信息,如下图:

我们一般关注逻辑读的次数,当多个表联合查询时,这里会现时每一个表的IO信息,当某个表的逻辑读的次数很大时,你就要重点关注和分析这个表了,是不是查询时涉及到这个表中的记录条数过多,是不是没有合理使用到Index,是不是可以增加其它的过滤条件来减少相关的记录集合等等。下面是简单说明:
输出项 含义
Table 表的名称。
Scan count 执行的索引或表扫描数。
logical reads 从数据缓存读取的页数。
physical reads 从磁盘读取的页数。
read-ahead reads 为进行查询而放入缓存的页数。
lob logical reads 从数据缓存读取的 text、ntext、image 或大值类型 (varchar(max)、nvarchar(max)、varbinary(max)) 页的数目。
lob physical reads 从磁盘读取的 text、ntext、image 或大值类型页的数目。
lob read-ahead reads 为进行查询而放入缓存的 text、ntext、image 或大值类型页的数目。
磁盘IO相关信息先介绍到这里,另外一个参考数据是使用 set statistics time on 参考显示分析、编译和执行语句所需的毫秒数。具体的使用方法同set statistics io on 基本相同,只不过显示的是本次查询所使用的分析编译、执行等的时间信息。聪明的你一定一看就明白了。在此不再赘述。

- 使用 set statistics profile on 参考显示当前语句执行的配置文件信息,执行步骤等信息,使用方法同上。
执行查询后,除了显示所执行的结果集合外,还另外显示本次sql语句执行的相关配置信息,采用记录树的形式显示,对应执行计划中的各个步骤,比如某个步骤使用的索引类型,评估行数,IO信息,时间信息等。这些信息都可以用来参考,以确定该段sql语句的问题在哪里。
参考当前语句的估计的执行计划或实际的执行计划,分析当前语句执行时SQL Server 查询优化器所选择的数据检索方法。