MySQL索引分类 最左匹配原则与失效场景解析
数据库索引作为提升查询效率的关键技术,其原理与书籍目录相似,通过优化数据检索方式显著降低查询复杂度。本文将深入解析MySQL索引的分类体系与核心工作机制。
索引是什么?有什么好处?
索引本质上是一种优化查询性能的数据结构,将全表扫描的O(N)时间复杂度优化为基于B+树结构的O(logdN)复杂度。具体优势体现在:
- 未使用索引的查询需要进行全表扫描,效率较低
- 使用索引后可通过二分查找算法快速定位目标数据,InnoDB引擎默认采用B+树结构实现
讲讲索引的分类是什么?
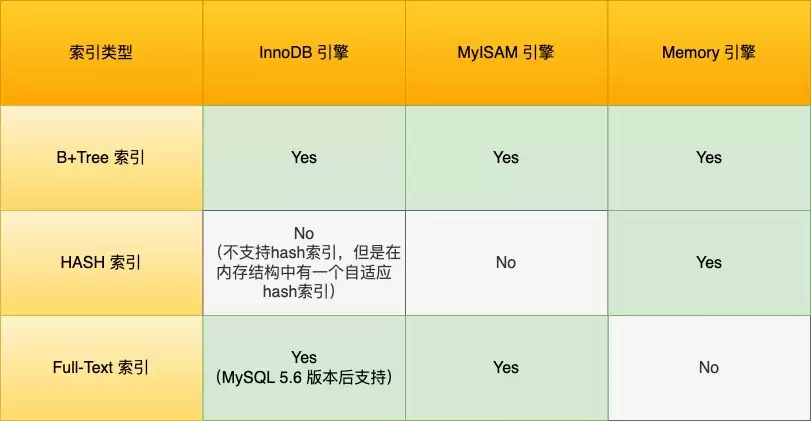
MySQL索引系统主要包含四种分类维度:
数据结构维度:B+Tree索引、Hash索引、Full-text索引
物理存储维度:聚簇索引(主键索引)、辅助索引(二级索引)
字段特性维度:主键索引、唯一索引、前缀索引、普通索引
字段数量维度:单列索引、复合索引(联合索引)
按数据结构分
基于不同数据结构可分为三种索引类型:
B+Tree索引
在InnoDB的聚簇索引中:
- 非叶子节点存储索引键值和下层指针
- 叶子节点保存完整行数据
- 定位到叶子节点即可获取完整记录
对于 InnoDB 的二级索引 (Secondary Index)
- 非叶子节点存储索引键值和指针
- 叶子节点仅保存索引值和主键值
- 需要回表查询才能获取完整数据
Hash索引基于哈希表实现,查询效率接近O(1),但仅支持精确匹配
Full-text索引采用倒排索引结构,适用于文本搜索场景
后两种索引均属于二级索引范畴
倒排索引的核心原理是建立关键词到文档位置的映射关系,与传统的正排索引形成对比
| 特性 | Hash 索引 | Full-Text 索引 |
|---|---|---|
| 核心设计 | 精确匹配(等值查询) | 自然语言搜索(关键词匹配) |
| 典型查询 | WHERE col = "abc" | WHERE MATCH(col) AGAINST("关键词") |
| 不支持 | 范围查询(>、<、BETWEEN)模糊查询( | 普通的 = 或 LIKE 查询(效率极低) |
| 底层算法 | 哈希表 | 倒排索引(Inverted Index) |
| 主要用途 | 高性能的简单键值查询 | 搜索引擎风格的内容搜索 |
| 引擎支持 | 主要是 Memory 引擎 | 仅 InnoDB、MyISAM 引擎 |
InnoDB引擎会根据表结构自动选择索引键:
1.优先选择主键作为聚簇索引
2.若无主键则选择首个非空唯一列
3.两者都不存在时自动创建自增ID
需注意主键索引和二级索引默认均使用B+Tree结构
按物理存储分
根据数据存储方式可分为两类:
聚簇索引的叶子节点直接存储完整数据记录
二级索引的叶子节点仅保存主键值
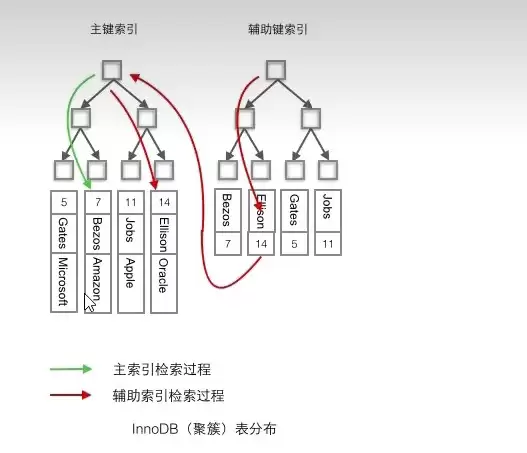
当查询数据存在于二级索引时称为覆盖索引,否则需要先获取主键再查询主键索引,这个过程称为回表
按字段特性分
根据字段特性可分为四种索引类型:
包括基于主键、唯一值、字段前缀和普通字段建立的索引
主键索引创建语法:
CREATE TABLE table_name ( .... PRIMARY KEY (index_column_1) USING BTREE);
唯一索引创建方式:
CREATE TABLE table_name ( .... UNIQUE KEY(index_column_1,index_column_2,...) );
表后创建唯一索引:
CREATE UNIQUE INDEX index_name ON table_name(index_column_1,index_column_2,...);
- 普通索引
普通索引适用于常规查询字段:
CREATE TABLE table_name ( .... INDEX(index_column_1,index_column_2,...) );
表后创建普通索引:
CREATE INDEX index_name ON table_name(index_column_1,index_column_2,...);
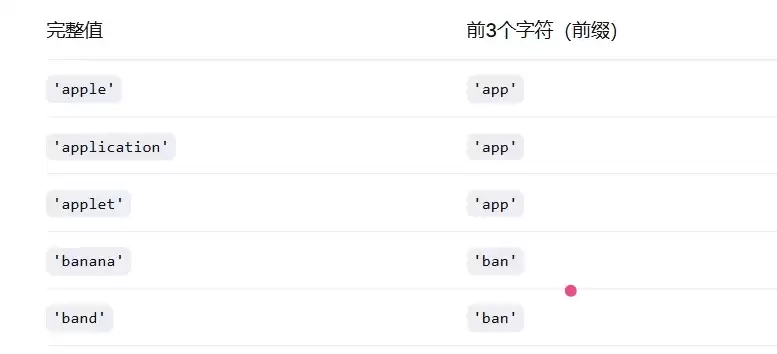
- 前缀索引
前缀索引通过截取字段前几位字符建立:
CREATE TABLE table_name( column_list, INDEX(column_name(length)));
表后创建前缀索引:
CREATE INDEX index_name ON table_name(column_name(length));
查询示例:
查询语句:
SELECT * FROM articles WHERE content = 'apple';
前缀索引查询流程:
- 截取查询值前N个字符
- 在索引中定位对应前缀
- 获取匹配的主键列表
- 回表查询完整数据
- 精确过滤最终结果
按字段个数分类
根据涉及字段数量分为:
- 单列索引:仅包含单个字段
- 联合索引:组合多个字段建立
创建联合索引语法:
CREATE INDEX index_product_no_name ON product(product_no, name);
联合索引底层采用双向链表结构:
