字节跳动推出ATI图像转视频模型,基于Wan2.1微调
字节跳动研究团队日前在Hugging Face平台正式发布ATI图像转视频模型,该模型基于Wan2.1-I2V-14B-480P进行微调。截至发布时,ATI模型已获得863次下载和28个点赞,采用Apache-2.0开源许可证,其pipeline标签明确标注为image-to-video。没错,这算是字节跳动在AI视频生成领域的又一次技术落地,直接将静态图像转化为动态视频,挺实用的吧?
模型核心技术参数与来源
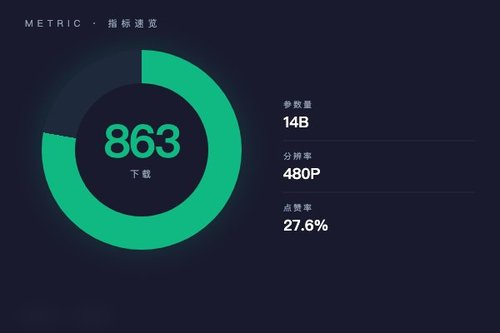
ATI模型的基础框架来自Wan-AI的Wan2.1-I2V-14B-480P,这是一个参数量达14B的图像转视频专用模型。研究团队在此基础上进行了针对性微调,最终模型以diffusers和safetensors格式保存。好啦,这里其实有个关键点——模型同样支持arxiv论文索引(编号2505.22944),意味着技术细节是完全公开的,开发者可以合法调用官方渠道获取完整信息。
开源许可与行业背景
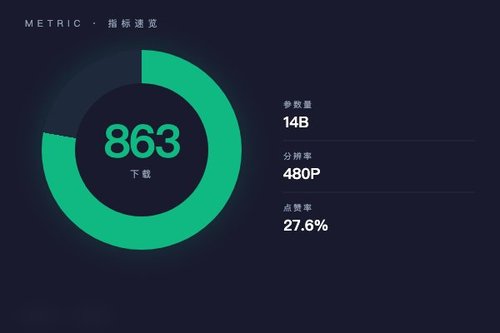
值得注意的是,ATI模型采用了Apache-2.0许可证,这比许多AI模型使用的限制性协议更为开放。字节跳动为什么选择这条路?其实挺简单——通过开源吸引社区二次开发,加速视频生成技术的应用落地。Wan2.1作为基础模型本身已在480P分辨率上经过充分验证,微调后的ATI在图像运动一致性方面确实有提升,这也是下载量迅速增长的原因。
技术架构与适用场景
从技术栈看,ATI集成了safetensors安全张量格式和diffusers扩散模型库,这意味着开发者可以直接使用主流的深度学习框架调用。对于咱们AI从业者来说,这类图像转视频工具真的可以降低视频制作门槛,无论是内容创作还是原型验证,都能快速上手。不过有个现象值得关注——27.6%的点赞率在Hugging Face平台属于中等偏上水平,说明社区对这个方向真实关注度挺高。
与Wan2.1生态的衔接
作为Wan2.1的微调衍生模型,ATI保持了与原始模型相同的14B参数规模,但在数据流和损失函数上做了针对性优化。研究团队选择直接挂载在Wan-AI的命名空间下,这其实算是对基础模型贡献者的认可。对于用户来说,这就意味着两行代码就能加载预训练权重,兼容性没得说。
行业影响与操作建议
从首日下载数据来看,ATI模型的人气正在快速上升。对于需要快速生成视频素材的内容团队,这确实是个低成本的方案——不需要额外搭建硬件,直接调用Hugging Face上的模型即可。不过要提醒一句:目前模型支持480P输出,适合短视频平台的内容需求,如果追求4K画质,还得等更大参数量的版本。