字节跳动Wan2.1-14B图像提示视频生成模型上线
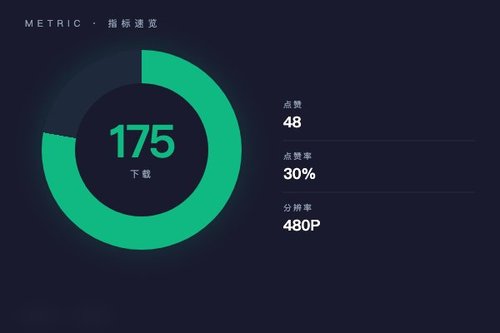
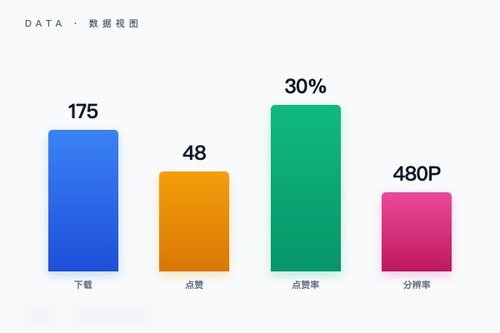
字节跳动日前在Hugging Face平台上正式上线了Video-As-Prompt-Wan2.1-14B图像提示视频生成模型。这个模型直接把视频片段当作“提示词”来驱动AI生成内容,目前已经获得了175次下载和48个点赞。可以说,这是目前AI视频生成领域又一个务实的举动——它真的把用户输入的影像素材变成了创作起点。
视频也能当提示词,凭什么?以往我们常见的“图生视频”模型,通常只接受一张静态图片作为输入,但字节跳动这次的做法挺有意思:它允许用户上传一段视频片段,然后基于这段画面的风格、动作和场景,生成新的连贯视频。模型基于Wan-AI/Wan2.1-I2V-14B-480P-Diffusers底座进行微调,还附带了BianYx/VAP-Data数据集和arxiv论文。它的pipeline_tag明确标为“image-to-video”,但实际能力已经超出了单纯的图片驱动——这不就是在用一种更直观的方式让人和机器对话吗?
技术细节上,模型采用了diffusers框架并集成了safetensors权重格式,这意味着开发者可以直接用WanImageToVideoPipeline进行调用。整个模型以Apache-2.0许可证对外开放,算是给开源社区又添了一把火。但问题来了:字节跳动在视频生成赛道上的速度怎么这么快?从今年早些时候Wan2.1系列的发布,到现在直接上线视频提示版本,节奏确实紧凑。
各家厂商都在抢视频生成这个风口。OpenAI的Sora虽然热度高但还未全面开放,Meta的Movie Gen也还在打磨,而字节跳动这边已经拿出一个能直接用视频片段“喂”给AI的成品。这是不是意味着,咱们国内团队在产品落地上已经跑到了前面?模型本身支持480P分辨率输出,虽然规格不算顶级,但胜在门槛低、上手快——下载量才175次,说明这个工具还处在早期扩散阶段,但点赞率接近30%足以说明社区对它挺认可。
最后聊点实际的。这个模型背后用到了Hugging Face平台现成的diffusers管线,这意味着如果你手头有合适的GPU,理论上可以直接在本地跑起来。而Apache-2.0许可更是给了开发者极大的自由度——想商用?想改造?悉听尊便。字节跳动这次没藏着掖着,反倒让人好奇:它接下来是不是还要把更大的模型或者更高清的版本也开源出来?毕竟,视频生成这盘棋,光有技术可不够,生态才是真正的护城河。