阿里巴巴发布8B深度研究智能体Marco-DeepResearch
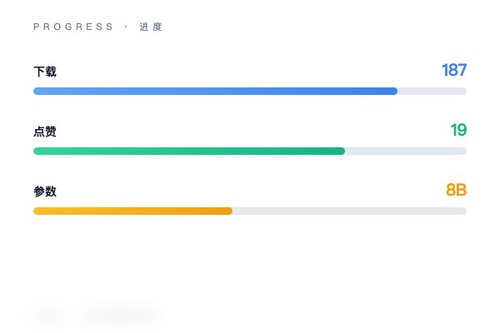
阿里巴巴旗下AIDC-AI团队发布Marco-DeepResearch-8B深度研究智能体,该模型基于Qwen3架构,专为自动化信息检索与验证设计。目前模型在Hugging Face上获得187次下载与19个点赞,标签包括deep-research、agent、web-search等,定位为开源文本生成工具,说实话这规模在开源社区里挺受关注的。
Marco-DeepResearch-8B的核心能力
模型主打深度研究智能体功能,能自主完成信息检索、多源验证与结果整合。它依靠ReAct循环实现推理与行动的结合,说白了就是让AI自己上网查资料,再交叉核对信息的可信度。这功能其实挺实用的,毕竟现在AI生成内容最怕的就是胡编乱造对吧?
标签背后的技术细节
从Hugging Face页面可以看到,模型兼容transformers库并使用safetensors格式存储权重,这意味着开发者可以直接在主流框架中调用。它的pipeline标签是text-generation,但实际能力远超简单对话——通过集成web-search与verification模块,它能完成需要多步推理的复杂研究任务。咱们想想看,8B参数量的模型能做到这一步,是不是比想象中能打?
开源策略与社区反应
AIDC-AI选择将模型完全开源,允许开发者下载权重并自行部署。目前187次下载量虽不算爆发式增长,但对于刚发布的垂直模型来说,已经算是个不错的起点。有意思的是,模型标签里同时出现了agent与information-seeking,确实说明了它不止是语言模型,更是一个可自主规划研究路径的工具。
对行业应用的真实价值
这类深度研究智能体最适合的场景,其实是需要快速整理大量公开信息的领域,比如竞品分析、学术文献综述或技术调研。以前咱们做这类工作得手动翻几十个网页,现在AI可以边搜索边核对,效率提升不止一星半点。凭什么不试试呢?这模型至少让自动化研究平民化了一大步。
最后得说一嘴,8B参数跑通深度研究管线真的不容易,毕竟既要保证检索覆盖率,又要控制推理成本。AIDC-AI这次拿出的方案,在开源社区里算是给出了一个挺有意义的参照系——至少证明了小规模模型也能玩转高级智能体功能,而不是非得堆到千亿参数才行。