月之暗面发布Kimi-Audio-7B音频语言模型
月之暗面发布Kimi-Audio-7B音频语言模型
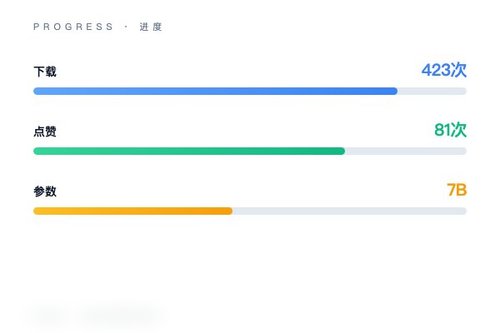
2025年7月1日,AI初创公司月之暗面(Moonshot AI)在Hugging Face平台正式发布了其最新的开源音频语言模型——Kimi-Audio-7B。该模型迅速引起开发者社区关注,截至目前已获得423次下载和81次点赞。这确实是一次重磅更新,标志着月之暗面在拓展多模态AI能力上迈出了关键一步。
Kimi-Audio-7B被归类为“文本转语音”模型,但它的能力远不止于此。根据官方标签,它同时支持音频理解、语音识别、音频生成以及对话交互。没错,一个模型就涵盖了音频输入输出的双向通道。凭什么一个7B参数量的模型就能搞定这么多任务?月之暗面对此的答案是:通过统一的架构设计,让模型既“听得懂”也“说得出”。
核心能力与参数亮点
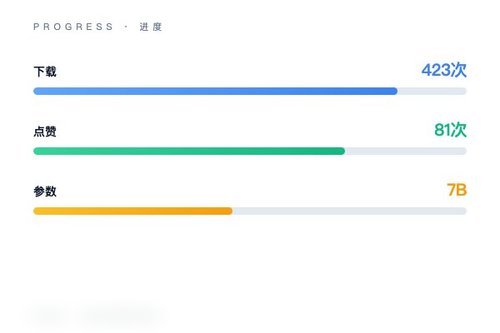
模型的参数规模为7B,采用了safetensors格式存储权重。与市面上其他专注单一任务的音频模型不同,Kimi-Audio-7B极有可能整合了编解码与理解模块。想象一下,你对着它说一段话,它能立刻识别内容,理解情绪,并以合适的语调回复你——这挺像科幻电影里的场景,对吧?不过现在它是真实可用的开源模型了。
从实际应用角度看,Kimi-Audio-7B的推出直接冲击了语音助手、有声内容生成和实时翻译等多个领域。尤其是“音频理解”能力,意味着模型能够从嘈杂环境中提取关键信息。例如在会议录音中直接定位某位发言人的指令。这样一来,咱们日常使用的语音工具或许很快就该换代了。
开源生态与行业冲击
月之暗面选择在Hugging Face平台以开源形式发布模型,并且代码标签中包含“custom_code”,这暗示开发者可以针对自身场景进行微调。这种策略其实挺聪明的——利用社区力量加速模型迭代,同时反向吸收第三方应用案例。不过,7B参数的模型在本地部署仍有门槛,普通用户得依赖云端接口才行。
一个值得思索的问题是:当音频语言模型能同时做到理解、生成与对话,传统的语音识别+文本转语音这种流水线方案还有存在的必要吗?月之暗面的Kimi-Audio-7B已经用行动给出了答案——合并才是趋势。要知道,单一模型减少延迟和误差的效果立竿见影。
未来展望与开发者机遇
目前模型的下载数据和点赞数仍在快速攀升,开发者们可以立刻从Hugging Face仓库获取权重与推理代码。如果你正在做音频相关的AI应用,这个模型真的值得一试。它或许能帮你省去整合多个模型的麻烦,只需一次调用就能搞定一切。月之暗面通过Kimi-Audio-7B向行业传递的信号很明确:音频AI的“大一统”时代,已经开始了。