HuggingFaceTB发布100M参数MoE文本生成模型nanowhale-100m
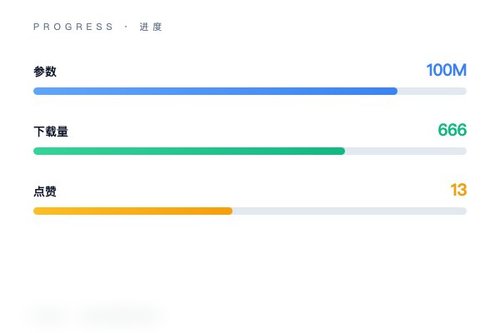
HuggingFaceTB发布了100M参数MoE文本生成模型nanowhale-100m,该模型基于DeepSeek v4架构,采用混合专家(MoE)结构,参数规模为100M,定位是轻量级文本生成。模型已在Hugging Face平台上线,仓库名称为HuggingFaceTB/nanowhale-100m-base,截至目前下载量达到666次,获得13个用户点赞,初步反馈还算积极。
具体来看,nanowhale-100m属于因果语言模型(causal-lm),训练时按照从左到右的顺序预测下一个token,这使得它特别适合对话、故事续写等连贯文本生成任务。它经过了预训练(pretrained),下游用户可以直接使用或微调。标签中的transformers表明它兼容Hugging Face的Transformers库,用几行代码就能加载和推理;safetensors则是一种安全的张量存储格式,能防范序列化漏洞,挺让人放心的。
模型的另一大亮点是MoE混合专家结构,这也是DeepSeek v4系列的标志性设计。MoE的核心思想是将网络分成多个专家模块,每次推理仅激活其中一部分,从而在保持模型容量的同时降低计算量。在100M参数这个规模上应用MoE,其实并不多见——大多数MoE模型体量较大。为什么不直接上大模型呢?因为很多实际场景对延迟和内存有严格要求,小MoE模型正好能满足这些需求,可以说是一个巧妙的平衡。
除了技术细节,模型的标签中还有custom_code,暗示它包含自定义代码,开发者可以灵活修改。这种开放性有助于社区进行二次创新。没错,开源社区里这样的小模型往往能激发各种实验和改编,咱们可以期待后续是否有基于它微调的版本出现,比如针对特定领域的对话模型。

从下载量666来看,关注度尚可;13个点赞虽然不多,但点赞/下载比例约2%,在发布初期算是不错的表现。确实,HuggingFaceTB这次发布为文本生成领域增添了一个轻量级选择,它说明了即使在资源有限的条件下,MoE架构也能发挥作用,而不是只有大模型才能胜任。
这样的尝试,难道不值得我们关注吗?