HuggingFace发布ORPO训练141B参数Mixtral文本生成模型
HuggingFace 日前通过其官方模型库发布了一款全新的文本生成模型——HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1。该模型基于 Mixtral 架构,采用 ORPO 训练方法,参数规模达到 141B(实际激活参数约 35B),在文本生成与对话任务上展现出挺强的竞争力。
模型核心指标与架构
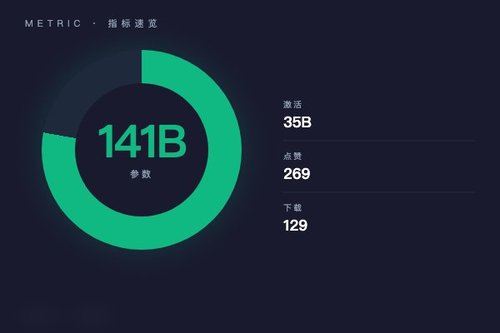
从 HuggingFace 页面数据看,这款模型目前已获得 269 个点赞与 129 次下载,标签涵盖 transformers、tensorboard、safetensors、mixtral、text-generation、trl、orpo 等。它属于标准的 text-generation pipeline,意味着咱们可以直接用它来生成对话、文章、代码等多种文本内容。说实话,141B 的总参数配合 35B 的激活参数,这种“稀疏激活”设计真的能在推理效率和模型能力之间取得不错的平衡。
ORPO 训练方法有何不同?
ORPO(Odds Ratio Preference Optimization)是一种新型的对齐训练策略,它在传统监督微调之后直接引入偏好优化,不需要单独的价值模型或奖励模型。这就让训练流程变得更简洁,同时也让模型在遵循人类偏好时表现更稳定。凭什么说它有效?从 HuggingFace 团队将其用于 141B 量级模型这一举动就能看出——他们确实对 ORPO 的扩展性有信心。
训练数据与适用场景
根据页面信息,该模型使用了 argilla/distilabel-capybara-dpo-7k-binarized 数据集进行训练,这是一个经过 DPO 标注的对话数据集,质量相当高。因此,zephyr-orpo-141b 特别适合构建聊天机器人、客服助手、内容生成工具等场景。没错,对于需要“听话”又“智能”的文本生成任务,这个模型可以说是一个很值得尝试的选择。
开源生态与社区反应
HuggingFace 一直坚持开源路线,这款模型也遵循同样的理念——模型权重、训练配置、评估指标全部公开。社区在发布后迅速给出了积极反馈,269 个点赞对于刚上线的模型来说已经算是相当不错的开局了。其实,这也反映出开发者对 ORPO 训练方案和 Mixtral 架构组合的期待:它能否在推理成本可控的前提下,达到接近甚至超越同规模密集模型的效果?
小结与展望
总的来说,HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 的发布为大语言模型社区又增添了一个高性价比的选项。它用 ORPO 方法完成了 141B 参数的对齐训练,实测效果值得后续关注。如果你正在寻找一个开源、可商用、对话能力强的文本生成模型,这个项目真的值得去试试看!