OpenGVLab推出ScaleCUA-32B视觉语言模型
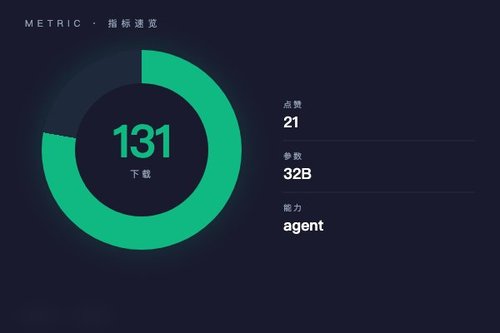
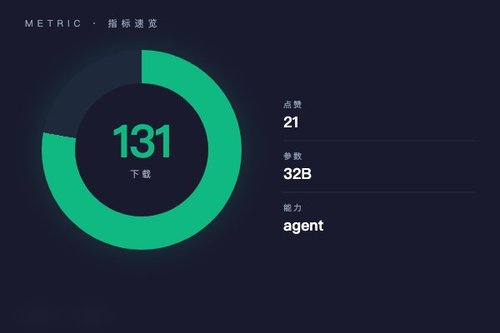
OpenGVLab日前正式发布ScaleCUA-32B视觉语言模型,该模型基于Qwen2.5-VL-32B-Instruct微调而成,专为图像与文本交互场景设计。截至发稿,模型在Hugging Face平台已获得131次下载和21个点赞,标签涵盖transformers、safetensors、agent、conversational等多个方向。
模型架构与数据基础
ScaleCUA-32B的基座模型来自阿里的Qwen2.5-VL-32B-Instruct,OpenGVLab在其基础上进行微调,并使用了自研的ScaleCUA-Data数据集。这意味着模型继承了Qwen2.5-VL强大的视觉语言理解能力,同时针对智能体(agent)和对话任务做了专项优化。其实,这类模型挺适合需要同时理解图片和文字内容的场景,比如文档问答、图表解析等。
技术亮点:从“看”到“做”的跨越
该模型的pipeline标签为“image-text-to-text”,即输入图像加文本,输出文本。但它的价值不止于此——标签中明确包含“agent”,说明它被设计成能执行简单任务的智能体。何来这种能力?正是通过ScaleCUA-Data数据集里的多轮交互样本训练出来的。你能想象吗?一个模型看完一张操作截图,就能直接生成下一步操作指令。
社区反响与实用性
虽然131次下载和21个点赞在热门模型里不算高,但对于刚发布两三天的项目来说,这个关注度已经算不错了。OpenGVLab在视觉语言模型领域一直挺活跃,这次ScaleCUA-32B算是他们对“具身智能”方向的一次试探吧。如果你正在做自动化办公、UI自动化或者图片内容理解,确实可以去试试这个模型。
与其他模型的对比思考
目前市面上类似的视觉语言模型不少,但ScaleCUA-32B的独特之处在于它把“视觉理解”和“任务执行”结合在了一起。它凭什么能做得更好?因为训练数据里包含了真实的操作轨迹,而不仅仅是图片描述。这就让模型学会了“看完图后该做什么”,而不只是“看图说话”。
一点提醒
注意模型的基础是Qwen2.5-VL-32B-Instruct,所以推理部署时你需要准备相应的GPU资源。OpenGVLab在Hugging Face上提供了safetensors格式的权重,下载起来很方便。别忘了,使用时要遵守Qwen2.5-VL的开源协议。