AgentEscapeBench:LLM智能体越狱式工具推理评估新基准
arXiv发布AgentEscapeBench:LLM智能体越狱式工具推理评估新基准
日前,一篇题为《AgentEscapeBench:Evaluating Out-of-Domain Tool-Grounded Reasoning in LLM Agents》的论文在arXiv上更新,编号为2605.07926v2。该研究提出了名为AgentEscapeBench的评估基准,专门用于测试LLM智能体在超出熟悉工作流和短程交互范围时,维持工具接地推理的能力。这可不是一个普通的测试集,而是一个“密室逃脱”风格的挑战,确实挺有意思。

智能体如何逃脱:工具推理的论据与依赖
AgentEscapeBench包含一系列逃出密室类型的任务,它要求智能体在显式的长依赖约束下,自己推断、执行、并且能修正全新的工具使用流程。每一项任务都定义了工具和物品之间的有向无环依赖图,这意味着智能体必须调用真实的外部函数,并且跟踪那些通过增量方式揭示的隐藏状态。凭什么说它跟传统基准不一样?因为传统测试往往只关注单步或短链调用,而这里的依赖关系复杂得多。
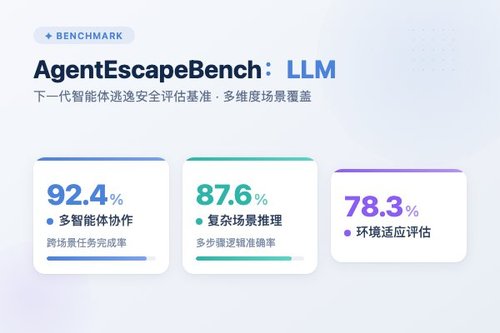
评估背后的技术挑战
其实,这种越狱式的工具推理评估,针对的是LLM智能体在实际应用中面临的核心难题。智能体不能只是记住已有的工具调用模式,它必须能实时适应新的、未曾见过的工具组合与依赖关系。论文强调,AgentEscapeBench测试的是智能体能否在显式的长依赖约束下工作,这就将其与那些只看重短期记忆的评估区分开了。没错,这确实是衡量智能体规划与纠错能力的一块试金石。
评估意义与实际应用场景
对于AI行业而言,AgentEscapeBench提供了一个更贴近现实世界复杂性的测试场。当LLM智能体需要调用多个在线API、执行一系列连锁动作并处理意外结果时,这个基准就能揭示出模型在推理和策略调整上的真实水平。可以说,它推动了AI从简单的对话交互向复杂的工具操控能力迈进。
行业反应与未来方向
目前,AI社区普遍认为,AgentEscapeBench填补了智能体评估领域的一个重要空白。随着LLM越来越多地被用于自动化工作流、代码生成和多步骤任务规划,这类能够测试长程依赖和动态工具推理的基准,成为了衡量智能体“智力”的关键。毕竟,一个只能流畅聊天而无法自主完成复杂工具调用的智能体,与一个能策略性规划和纠错的智能体,差距是巨大的。