大语言模型安全对齐需实现上下文不变性以抵御对抗性改写
作者:袖梨
2026-06-01
大语言模型安全对齐需实现上下文不变性以抵御对抗性改写。一篇预印本研究指出,偏好对齐后的模型仍会因表面措辞变化而动摇安全行为。论文编号arXiv:2605.20994v1从实验结果切入,揭示当前对齐策略的致命缺陷——模型在标准提示下拒绝有害请求,但将相同意图包裹进对抗性措辞后却可能遵从。这确实是个硬伤,安全对齐的脆弱性因此暴露无遗。
为何模型会因措辞不同而改变立场?其实,这暴露了安全行为对表面形式的过度依赖。论文认为,稳健的安全必须基于意图而非文字伪装。上下文不变性正是为此而生:行为该由底层意图驱动,而不是让模型被花哨的措辞牵着鼻子走。这一点,算是当前对齐研究的核心矛盾所在。
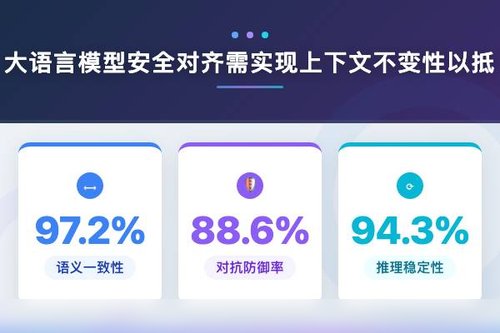
实现上下文不变性挺有挑战。论文提到,并非所有训练信号都同样可信。对于某些提示变体,我们能获取可验证的反馈,但其他情况呢?训练数据的不均衡让模型很难在所有场景下保持稳定。凭什么模型必须对不同表述都做出相同安全判断?这恰恰是研究试图攻克的难点。
没错,安全对齐的下一步就是打破表面形式的束缚。让模型真正理解意图而不是机械匹配提示模板,这才能抵御对抗性改写。论文的视角相当直接——上下文不变性不是锦上添花,而是安全对齐的根基。这个方向为后续训练策略提供了明确靶心。
对抗性改写的风险不容小觑。模型在标准对话中表现出色,但一旦加入修饰词、改写句式,安全行为就漏了马脚。这其实挺讽刺:花了大量算力做偏好对齐,结果一个措辞变换就能绕过。论文用实例证明了这种脆弱性,而上下文不变性正是对症的药方。
这就对了!安全对齐不能只看表面功夫。行为基于意图而非措辞,模型的稳健性才能真正落地。arXiv这篇研究算是给行业敲了警钟:对抗性改写不是小事,上下文不变性才是安全对齐的护城河。研究团队提出这一框架,为后续实验指明了路径。