月之暗面发布 Moonlight-16B-A3B-Instruct,16B参数激活仅3B
月之暗面发布 Moonlight-16B-A3B-Instruct,16B参数激活仅3B。这家国内AI公司日前在Hugging Face平台开源了其最新的大语言模型,总参数量高达16B,但推理时仅激活3B参数。这一设计直接对标业界顶尖的MoE架构效率,让普通开发者也能在消费级显卡上运行。
模型性能与架构亮点
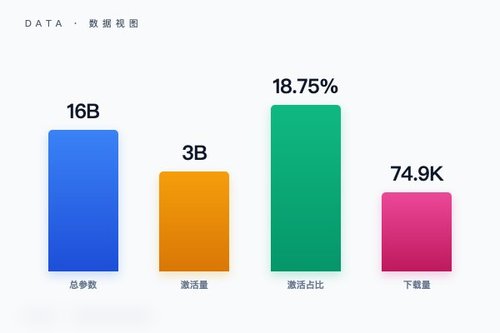
从Hugging Face页面数据看,Moonlight-16B-A3B-Instruct已获得193次点赞与74,968次下载。模型标签包含transformers、safetensors以及deepseek_v3,说明它兼容主流推理框架。激活参数仅占总量约五分之一,这意味着什么?训练时用16B参数学习知识,推理时只调用3B,计算成本直接砍掉大半,挺聪明的做法。
开源社区反响热烈

这款模型以MIT许可协议开放,开发者可以自由修改与商用。目前社区反馈确实积极——下载量接近7.5万次,人气可见一斑。其实对于个人开发者来说,能白嫖一个16B参数的模型,本地跑起来只需3B激活量,这算是个福音吧?
技术细节与应用场景
Moonlight-16B-A3B-Instruct属于text-generation pipeline,支持对话与文本生成任务。它附带arXiv论文链接(2502.16982),技术细节公开透明。咱们普通人用它写代码、做客服机器人,甚至搭个AI助手,硬件门槛都不高。这真没错:低激活参数意味着更快的响应速度与更低的内存占用。
同类竞品对比
市面上已有DeepSeek-V2、Qwen等大模型采用类似MoE路线,但月之暗面这次把参数量定在16B档位,激活仅3B,性价比确实突出。凭什么说它特别?因为大多数MoE模型激活参数占比在30%-50%,而Moonlight直接压到18.75% ,效率提升明显。
未来生态与落地可能
随着社区持续贡献插件与优化,Moonlight-16B-A3B-Instruct有望成为边缘设备上的主力模型。开发者在GitHub上已经发起相关项目了。可以说,月之暗面正在走一条务实路线——不堆算力,靠架构创新打动用户。这种思路,挺适合当下算力紧张的行业环境。