智源研究院发布Emu3.5视觉分词器模型
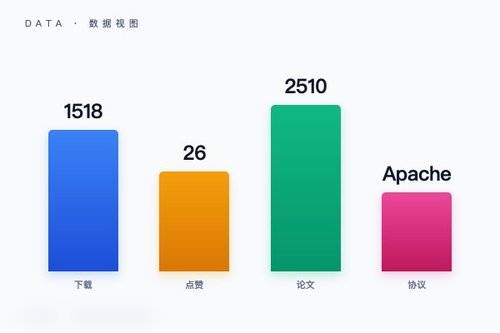
智源研究院日前在 Hugging Face 平台正式发布 Emu3.5 视觉分词器模型(BAAI/Emu3.5-VisionTokenizer),该模型上线后已获得 1518 次下载和 26 个点赞。
模型定位与技术细节。从标签信息来看,Emu3.5 视觉分词器模型采用 safetensors 格式存储权重,核心架构为 Emu3p5VisionVQ,并附带 arxiv:2510.26583 论文链接。模型遵循 Apache-2.0 开源协议,这意味着开发者可以合法地将其用于自身项目。但有意思的是,其标注的区域为美国(region:us),这背后反映的到底是服务器部署策略还是其他考量?
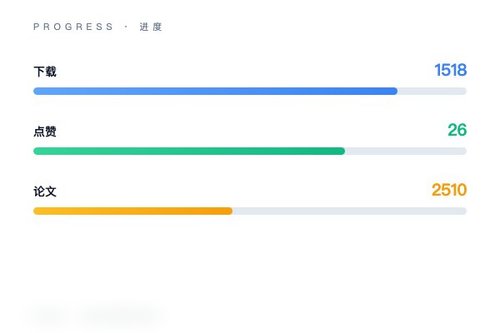
模型开源与社区反馈。截至目前,模型在平台上的交互数据并不算高,26 个点赞和 1518 次下载——这真的能代表社区的真实关注度吗?其实很多开发者习惯只下载不点赞,咱们不能单凭点赞数来判断模型价值。毕竟视觉分词器是一个相对专业的基础组件,并非面向普通用户的消费级产品。
技术路线与行业意义。智源研究院选择在视觉分词器方向发力,确实挺符合其推动国产开源生态的定位。Emu3.5 系列专注于视觉理解与生成任务,而分词器作为将图像转化为离散 token 的关键一步,直接影响下游模型效果。凭什么说它重要?没有好的分词器,后续视觉语言模型的训练效率与性能都会打折扣。
开发者如何使用。开发者可以通过官方渠道直接从 Hugging Face 下载模型权重和配置文件。需要注意的是,模型使用了自定义代码(custom_code),所以调用时需要确保环境正确。要是部署中遇到问题,不妨去开源社区翻翻相关讨论。
结语。智源研究院通过 Emu3.5 视觉分词器模型为中文视觉 AI 生态又添了一颗棋子。虽然现阶段下载量看起来不算惊艳,但基础工具的价值往往需要时间沉淀。这确实是一个值得关注的开源项目!