HuggingFace TRL v1.4.0 分块交叉熵损失降低 SFT 显存消耗至多50%
作者:袖梨
2026-06-01
HuggingFace TRL 库迎来 v1.4.0 版本更新,核心亮点是引入了分块交叉熵损失函数,在监督微调任务中可降低显存消耗至多50%。这一改动直接回应了大模型训练中硬件门槛过高的痛点,让更多研究者和开发者用更少资源跑通 SFT 流程。
分块交叉熵损失如何实现显存“瘦身”?
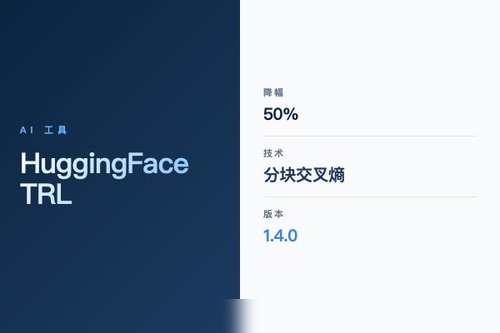
对开发者意味着什么?
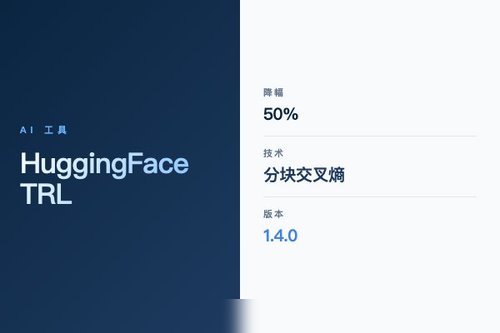
背后算力与硬件策略的博弈
降低显存需求,但并没有减少总的计算量——只是用时间换空间。分块交叉熵损失在降低峰值显存的同时,单卡训练的总时长可能会略有增加。但问题来了:在显存成为瓶颈的年代,多等几分钟换一块显卡的GPU预算,真的不值吗?尤其是那些被显存卡住脖子、连实验都跑不了的场景,这个trade-off完全可以接受。HuggingFace TRL 团队在v1.4.0中还优化了其他接口与文档,不过分块交叉熵损失无疑是此次更新的明星。可以说,这个特性让SFT训练变得更亲民,也为后训练阶段的资源优化提供了新的思路。如果你手头上有SFT任务且正被显存不足困扰,试试这个新方法——它确实值得重视。