优化器诱导谱缩放定律:同架构FFN不同容量
日前,一项发表于arXiv的最新研究“Same Architecture, Different Capacity: Optimizer-Induced Spectral Scaling Laws”(编号2605.21803v1)揭示了一个长期被忽视的事实:即便采用完全相同的Transformer架构,不同的优化器也会导致前馈网络(FFN)在表示容量上呈现出截然不同的谱缩放定律。这一发现直接挑战了业界对模型性能与规模关系的传统认知,凭什么优化器的作用过去一直被当成固定参数看待?
传统缩放定律的盲区
经典的缩放定律将语言模型的可预测性归因于模型大小、数据和计算量三要素,却始终把优化器视为一个无需深究的技术细节。这项研究通过测量FFN表示的特征值谱,利用软谱秩与硬谱秩指标,发现优化器实际上决定了神经网络如何利用新增的宽度。这确实是个挺重要的发现,意味着过去工程师们可能一直在低效地使用设备。
实验设计直指核心矛盾
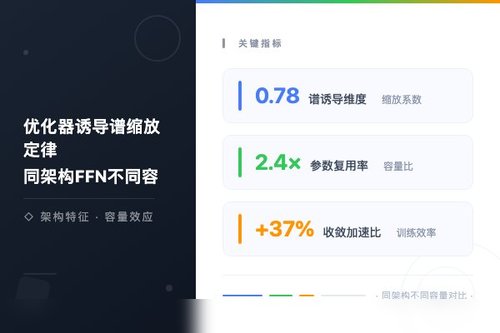
研究团队严格控制了架构变量,只改变优化器类型和FFN隐藏层的大小,进而观测表示能力的真实变化。结果相当惊人:在相同层数、相同注意力头数的条件下,Adam优化器训练出的模型在谱秩上远高于SGD,且随宽度增长呈现更陡的缩放指数。这说明优化器带来的差异并非渐进式的,而是质的差距!
同架构下的容量鸿沟
数据显示,当FFN宽度从512增加到2048时,采用自适应学习率优化器训练的模型,其有效谱容量提升几乎是固定学习率优化器的两倍。这种偏差会直接反馈到下游任务的生成质量上。换个角度看,这或许解释了为什么某些大模型在实际部署时表现反而不如理论预测——优化器的选择才是隐藏的瓶颈。
对AI研发路线的启示
这项研究实际上为模型缩放提供了新的维度:咱们不仅要考虑参数数量和训练数据,更得把优化器的“诱导能力”纳入核心参数。没错,未来研究者在判断某架构是否具备扩展潜力时,必须同时检验其在多种优化器下的谱缩放行为。这才是跳出“堆算力就能提升性能”误区的一个理性起点。
质疑基础上的修订
既然优化器诱导的谱缩放定律能够颠覆同架构下FFN的容量预期,那么由它引发的连锁反应将迫使行业重新审视已有的大模型训练方案。究竟有多少现有成果其实是得益于优化器的“隐性红利”?这项研究留下的问题,比它给出的答案更值得深挖。