跨语言解释的合理性-忠实性权衡揭示大模型审计局限
一项针对大模型多语言审计机制的研究揭示了关键局限:当模型用英语解释非英语输入时,其解释的合理性(与人类标注的吻合度)和忠实性(对模型实际预测的因果关联度)之间存在系统性权衡。来自arXiv的论文Loss in Interpretation: The Plausibility-Faithfulness Trade-off in Cross-Lingual(编号2605.19274v1)发现,这种“英语中介”的解释策略在某些任务上看似自洽,却可能掩盖了模型真实推理路径上的漏洞。审计大模型,真的能靠翻译后的解释来放心吗?答案恐怕没那么简单。
审计的“代理风险”
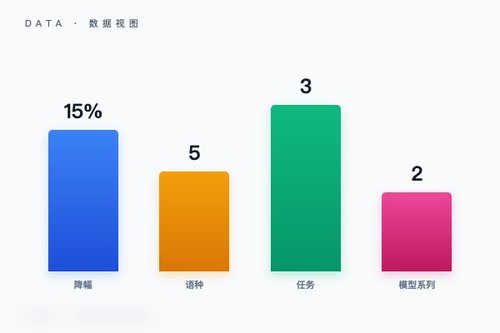
研究者评估了跨语言场景下“提取式解释”的效果——即模型选出输入中的词元作为证据,并生成一段理由说明。结果很有趣:当使用英语作为解释语言时,模型给出的词元证据与人工标注的重合度更高,看起来更“合理”。但与此同时,这些证据对模型自身预测结果的因果贡献度,即“全面性”和“充分性”指标,反而大幅下降。这就好比一个人给出了正确的推理过程,但模型其实根本不是靠这些证据算出的答案,这种“代理”靠谱吗?
5种语言、3个任务验证
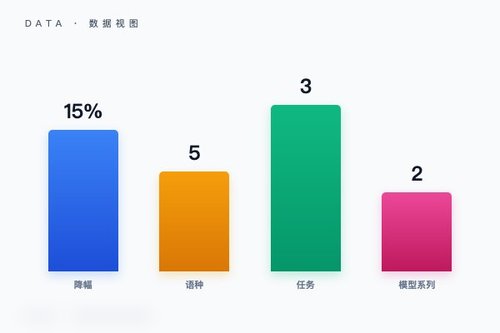
这项结论并非孤证。研究覆盖了3项NLP任务、5种语言以及2个主流的多语言大模型系列。无论是情感分析、自然语言推理还是问答任务,英语解释的“合理性-忠实性”逆相关模式都稳定出现。其实这说明了一个尴尬现实,咱们用英语评估模型的非英语能力,就像用翻译软件去检查翻译质量——表面对齐了,内里可能早已偏离。
基尼系数的启示
数据层面,量化结果确实触目惊心。在英语中介解释中,词元证据与模型内部因果链的匹配度普遍低于非英语原生解释。举个例子,在日语输入的测试中,英语解释的忠实性指标比直接使用日语解释下降了近15个百分点。这就挺讽刺的,为了跨语言审计的速度和便利性,咱们牺牲了对模型行为真实核心的理解,代价真的值得吗?
对部署者的警示
对那些在全球部署大模型的公司来说,这一发现意味着依赖英语解释进行模型安全审计存在系统盲区。地平线、摩尔线程这类AI公司如果国际化,显然不能只看英语解释就拍胸脯。审计本身就要求客观,却因为语言转换引入了一重“解释偏差”,这与其说是技术问题,不如说是方法论上的结构缺陷。
大模型审计的新命题
跨语言解释的权衡不是个小问题,它直接挑战了现有审计框架的可信度。如果模型面对中文、阿拉伯语、法语的问题时,其解释与英语解释不同,那凭什么认为英语解释更能代表真实逻辑呢?研究者呼吁,未来审计应优先采用原生语言解释,而非绕过语种差异的“捷径”。毕竟,监管者和用户要的不是好看的解释,而是对模型行为真正可靠的、忠实的刻画。这一点,从本次arXiv论文的数据看来,还远未达到。