多Agent LLM分布式信息集体推理存在系统性失败
作者:袖梨
2026-05-31
多Agent LLM分布式信息集体推理存在系统性失败
arXiv最新论文(编号2505.11556v4)揭示了基于大语言模型的多Agent系统在分布式信息环境下的集体推理存在系统性失败。研究团队推出HiddenBench基准,含65个任务,旨在隔离分布式信息下的集体推理与个体推理能力。
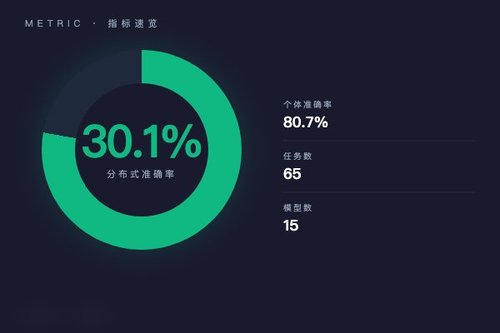
咱们来看关键数据:15个前沿LLM模型在分布式信息条件下仅达到30.1%的准确率,而个体推理准确率却高达80.7%。这差距挺大的吧?多Agent本该通过信息共享提升决策,结果却集体掉链子,何来系统性失败?原因就在于Hidden Profile范式——每个Agent只掌握部分信息,关键信息需要协作才能拼凑出来。
其实这30.1%的准确率是个警钟。多Agent系统号称能增强决策能力,但在HiddenBench测试中,它们无法有效整合分散信息。为什么?因为LLM在独立推理时表现不错,可一旦需要跨Agent共享并验证信息,系统就暴露出集体推理的短板——说白了,就是“三个臭皮匠”没顶个诸葛亮,反而互相拖后腿。

你可以说,这算是对当前多Agent架构的当头一棒。很多团队吹捧的“群体智慧”,在分布式信息面前被证明只是个体能力的简单加总,而非真正的协同。没错,单个模型能凭自身知识答对八成题目,但多Agent集体推理时信息被分割,系统就抓瞎了——失败不是偶然,是底层架构的硬伤。
多Agent LLM集体推理的失败很真实——分布式信息下准确率骤降50个百分点。这不仅是论文里的数据,更是对AI行业的一个提醒:盲目堆叠Agent数量,不如先解决信息共享机制。毕竟,咱们要的不是一堆勉强及格的学生,而是一个真正会协作的团队。