IBM发布Granite Vision 4.1-4B多模态视觉语言模型
IBM发布Granite Vision 4.1-4B多模态视觉语言模型
IBM官方在Hugging Face平台正式发布了Granite Vision 4.1-4B多模态视觉语言模型。这款模型面向图像文本理解任务,目前下载量已达到23832次,收获了73个点赞。它采用transformer架构并支持safetensors格式,在图像与文本的跨模态对话上展现了不错的实用性。算是一个比较轻量级的视觉语言模型,4B参数规模让它更容易部署。
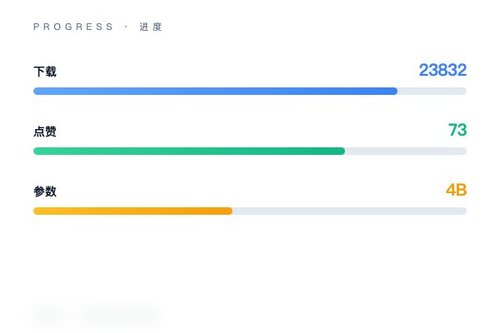
Granite Vision 4.1-4B到底能做什么?
从标签信息看,模型定位于“image-text-to-text”和“conversational”场景。这意味着它能接收图片加文字输入,然后输出对应的回答。这挺有意思——你给它一张图表照片,它可以解读数据;给它一个产品图,它能描述细节。目前社区里已经有73个用户点赞,下载量也在增长,说明大家对它挺感兴趣的。其实多模态模型这两年发展很快,但IBM这个版本走的是务实路线,专注在对话式交互上。
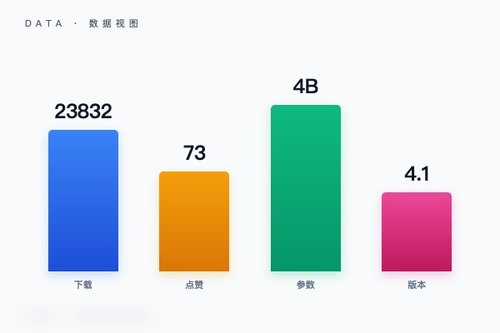
技术细节与背景
模型代码基于transformers框架实现,并引用了多篇arXiv论文,包括arxiv:2603.27064、arxiv:2208.00385和arxiv:2502.09927。这些研究为视觉编码和语言对齐提供了理论基础。说实话,4B参数在视觉语言模型中不算大,但IBM选择在这个规模上打磨,可能是为了降低硬件门槛。为什么这么说?因为很多同类模型动辄7B、13B参数,普通开发者根本跑不动,而4B参数可以在消费级显卡上推理,这就很香了!
模型标签里的秘密
在Hugging Face页面上,模型被标记为“granite4_vision”,并带有“custom_code”标签。这说明用户可以根据需求修改推理代码,灵活性挺高的。另外,它使用了“en”语言标签,意味着英文语料是训练主体。不过IBM一直强调企业级应用,所以后续推出多语言版本也是有可能的。咱们可以关注下它的许可证条款,毕竟商业部署的话合规性很重要。
社区反响与应用前景
目前模型下载量刚刚超过两万次,对于一款刚发布的开源模型来说,这个数字算是中规中矩。但别忘了,IBM Granite系列在AI圈子里有不错的口碑,尤其是企业用户比较信任它的稳定性和可控性。开发者可以直接在Hugging Face上测试demo,或者用transformers库快速集成。这就给自动化客服、文档分析、教育辅助等场景提供了一个新选择。难道这不比盲目追逐超大模型更实用吗?
总结
IBM Granite Vision 4.1-4B的发布,再次证明了中小规模多模态模型的潜力。它没有堆参数,而是把重点放在了易用性和社区支持上。对于想尝试视觉语言任务但又不想被硬件卡脖子的团队来说,这确实是一个值得入手的开源选择。