Toto 2.0 时间序列模型参数扩展至25亿,刷新三项基准
作者:袖梨
2026-05-30
Toto 2.0 时间序列模型日前将参数扩展至 25 亿规模,并在三项基准上刷新最高纪录。来自 arXiv 的论文证实,时间序列基础模型确实具备可扩展性:同一套训练方案从 400 万参数推进至 25 亿参数,预测质量稳步提升。这一成果由研究团队通过系统实验完成验证。
模型家族与训练方案
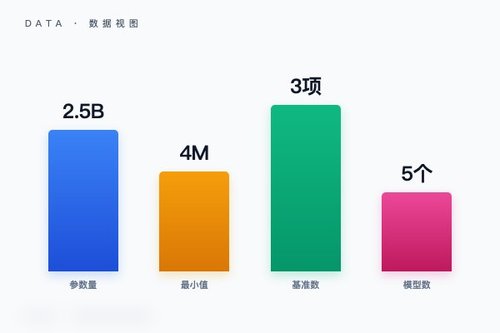
Toto 2.0 其实包含五个开源权重的预测模型,覆盖不同参数规模。研究团队发现,时间序列预测同样能吃规模红利——参数增长带来的是稳定且可复现的精度提升。可以说,这套训练方案为时序模型提供了一条清晰的规模化路径,不同资源条件的团队都能找到合适的版本。
三项基准全面领先

新模型在三个业界基准上拿了第一。BOOM 是团队自建的观测性基准,聚焦实际部署场景;GIFT-Eval 是通用的标准评估集,覆盖多种预测任务;TIME 则是最近推出的抗污染基准,专门考验模型对数据污染的鲁棒性。三项全胜的成绩确实挺有说服力,这不是小修小补能实现的。
从 400 万到 25 亿的跨越
这次发布挺有意思的一点是它首次系统验证了时间序列模型的规模扩展规律。从 4M 到 2.5B,三个数量级的参数增长,每一级都带来了可量化的预测精度提升。这为整个领域提供了实证基础,说明时序模型同样遵循规模效应,而不是靠运气。
开源与社区价值
团队把五个模型全部开源,这意味着咱们可以直接用这些预训练权重做推理或微调。这种开放姿态确实能加速技术迭代——毕竟自己从头训练一个 25 亿参数的模型成本太高了,开源降低了研究和应用的门槛,让更多人参与进来。
对时间序列领域的影响
Toto 2.0 的发布说明参数扩展在时间序列领域同样成立,不再是 NLP 和 CV 的专利。未来更大规模的模型或许会带来更多突破,咱们就等着看吧!