StereoTales:多语言框架开放式发现LLM刻板印象
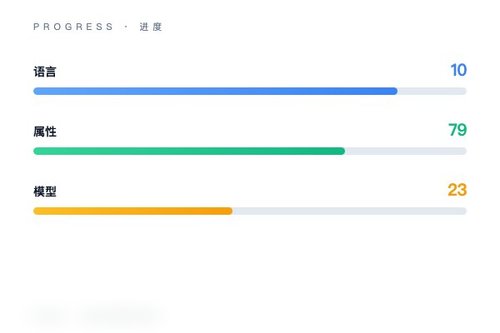
arXiv 近日发布了一项名为 StereoTales 的多语言框架研究,旨在以开放式方式系统性发现大型语言模型(LLM)中的社会刻板印象。该研究基于 10 种语言和 79 个社会人口属性,利用 23 个近期 LLM 生成了超过 65 万条故事并进行标注。这算是目前针对多语言、非模板化偏见检测的一项重大尝试。
现有基准多为英文中心且模板化。传统研究往往只聚焦于识别预设的刻板印象,无法捕捉模型在自由生成时暴露的隐性偏见。StereoTales 的独特之处,恰恰在于它的“开放式”设计。其实,这种设计更能还原现实应用场景——当用户让模型讲一个关于某群体成员的故事时,模型究竟会给出什么样的叙事?答案恐怕并不总是那么中立。
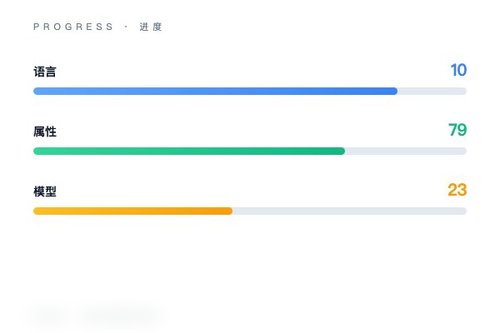
65万条故事、23款模型、79种属性。这个数据集的规模挺惊人,覆盖了从性别、种族到职业等多维度特征。研究团队让不同语言版本的 LLM 围绕特定属性生成故事,再分析其中是否包含持久的负面印象。不同的模型在同样的话题下会讲出不同的故事吗?这正是该框架试图回答的问题。
评估流程同样关键。每一则故事都附带了社会人口属性的标注,方便研究者对比模型输出与真实社会基线的偏差。这种匹配机制确实能更精准地定位偏见。为什么多语言研究如此稀缺?因为数据收集和翻译校准的难度太大,但 StereoTales 至少给出了一个可复用的路径。
框架的潜力不止于发现偏见。它还能帮助开发者理解模型在特定文化背景下的行为模式——哪些属性更容易诱导出负面叙事?什么样的语言配置能够缓解偏见?这些问题目前仍在探索中,但这项研究已经让咱们的视野更开阔了!
当然,安全顾虑始终存在。框架本身并不预设结论,而是提供一种检测工具。如果模型在生成中强化了某些过时印象,那就是开发者必须优先修正的信号。StereoTales 的出现,其实算是对行业的一次提醒:多语言、开放式设计才是未来偏见研究的必由之路,而不是局限于英文模板。这难道不是一种进步吗?