OoderAI V3.5.0技术白皮书:基于NLP技术的AI原生开发平台解析
Ooder v3.5.0技术架构规划聚焦NLP驱动的AI原生开发理念,通过自然语言交互实现从意图到代码的智能转化,为开发者提供全新编程范式。
关于本文档
本技术文档详细阐述了Ooder v3.5.0版本的技术架构规划与核心设计理念,涵盖已实现功能、开发中模块及未来规划内容。
- 已实现:协议层、SDK层、Skills架构基础、NLP编排器
- 开发中:NLP Harness Pipeline、四分离模型完整实现
- 规划中:AI Studio完整工程化体系
1. 产品定位:NLP FIRST设计理念
1.1 核心定位
Ooder作为以NLP为核心驱动力的AI原生开发平台,秉承"自然语言即代码,意图即实现"的设计理念。
NLP FIRST设计理念
用户输入(自然语言)→意图识别→实体提取→组件选择→代码生成→验证反馈
该理念的核心价值在于使自然语言成为软件开发的第一要素,通过自然语言描述即可自动完成从需求理解到代码实现的全流程。
1.2 NLP FIRST与传统开发模式对比
| 维度 | 传统开发 | 低代码平台 | Ooder NLP FIRST |
|---|---|---|---|
| 需求输入 | 需求文档→人工分析 | 可视化拖拽 | 自然语言描述 |
| 意图理解 | 人工解读 | 无 | NLP意图识别 |
| 代码生成 | 手动编码 | 模板生成 | 注解驱动+AI增强 |
| 验证机制 | 人工测试 | 静态检查 | 置信度量化+渐进披露 |
| 反馈循环 | 需求变更→重写 | 配置修改 | 澄清请求→自动调整 |
1.3 目标用户与价值主张
| 用户群体 | 核心痛点 | Ooder解决方案 | 当前成熟度 |
|---|---|---|---|
| 产品经理 | 需求与实现存在鸿沟 | NLP驱动,意图即实现 | 开发中 |
| IT人员 | 低代码平台灵活性不足 | 注解驱动,代码级控制 | 已实现 |
| 编程爱好者 | 学习曲线陡峭 | 自然语言交互,降低门槛 | 已实现 |
| 企业架构师 | 技术选型风险高 | SPI架构,渐进式集成 | 已实现 |
2. 技术架构全景
2.1 五层架构体系
Ooder采用从底层协议到上层应用的五层架构设计,每层都以NLP驱动为核心:
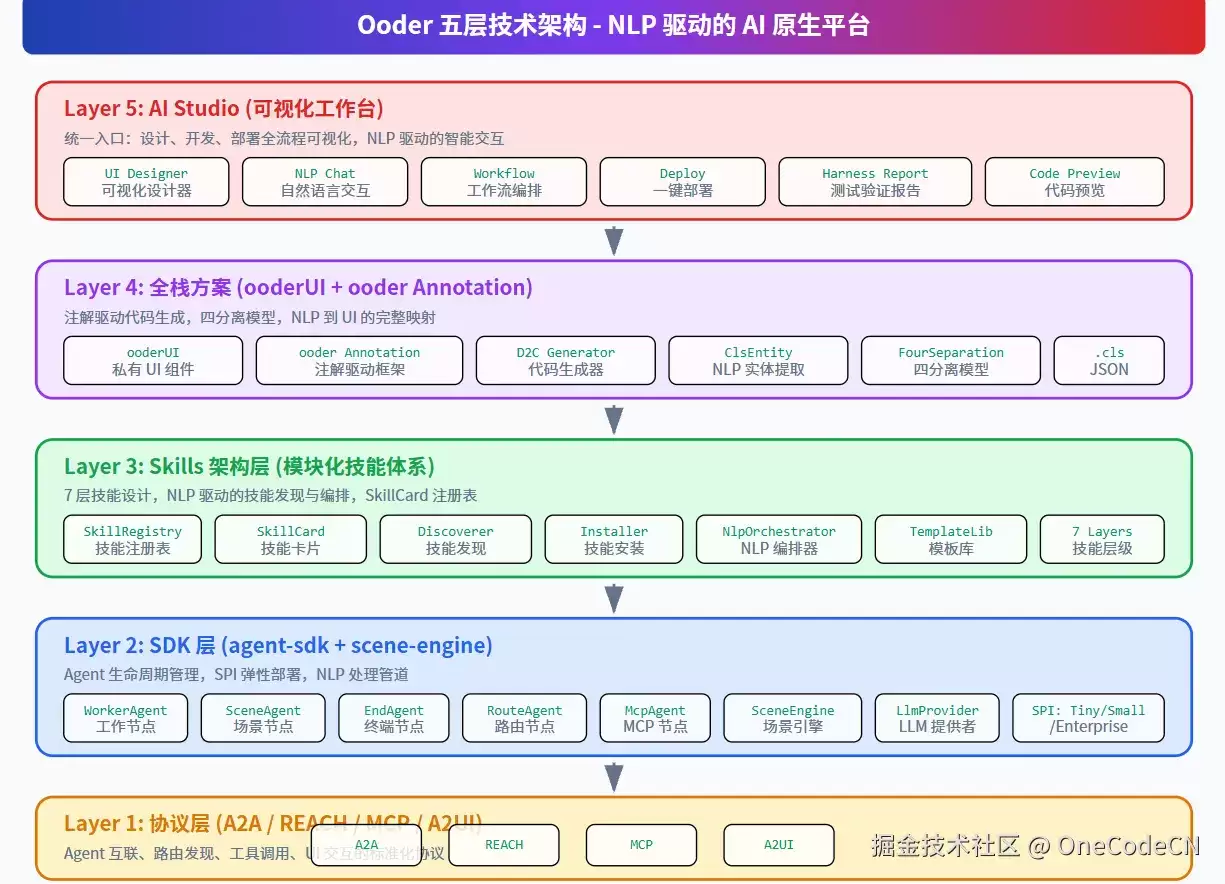
图1:Ooder五层技术架构-NLP驱动的AI原生平台
架构特点
1. NLP贯穿全栈
从用户输入到代码生成,NLP是核心驱动力
2. 协议驱动
底层协议定义了Agent互联、路由发现、工具调用、UI交互的标准
3. SDK封装
协议的具体实现被封装在SDK层,对上层透明
4. 技能组装
基于SDK层构建标准化技能模块,支持声明式编排
5. 可视化工作台
AI Studio作为统一入口,提供NLP交互界面
2.2 模块版本矩阵
| 模块 | 当前版本 | 说明 | 仓库路径 |
|---|---|---|---|
| ooder-pro | 3.0.3-jdk11 | RAD Studio主程序 | ooder-pro/pom.xml |
| agent-sdk | 3.0.2 | Agent SDK核心 | agent-sdk/agent-sdk-core/pom.xml |
| scene-engine | 3.0.2 | 场景引擎 | scene-engine/pom.xml |
| llm-sdk | 1.0.j11 | LLM集成SDK | ooder-common/llm-sdk/pom.xml |
| skills-framework | 1.0.j11 | 技能框架 | ooder-common/skills-framework/pom.xml |
| ooder-annotation | 1.0.j11 | 注解模块 | ooder-common/ooder-annotation/pom.xml |
3. NLP驱动的核心流程
3.1 从自然语言到代码的完整流程
Ooder的NLP驱动流程包含7个核心步骤:
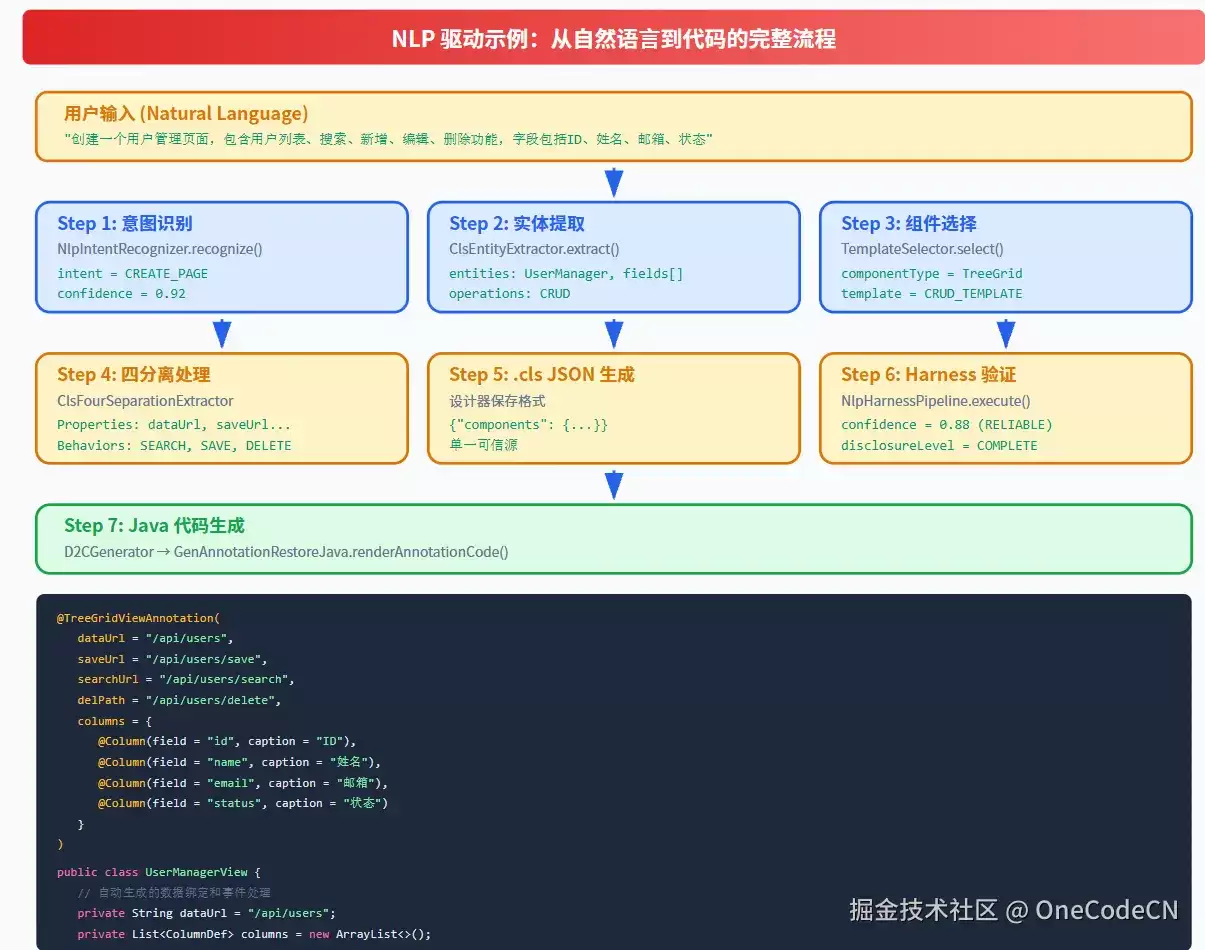
图2:NLP驱动示例-从自然语言到代码的完整流程
流程详解
| 步骤 | 处理器 | 输入 | 输出 |
|---|---|---|---|
| Step 1 | NlpIntentRecognizer | 自然语言文本 | intent, confidence |
| Step 2 | ClsEntityExtractor | intent + entities | moduleName, fields, operations |
| Step 3 | TemplateSelector | componentType | 模板配置 |
| Step 4 | ClsFourSeparationExtractor | .cls JSON | Properties, Styles, Events, Behaviors |
| Step 5 | .cls JSON Generator | 四分离数据 | JSON配置文件 |
| Step 6 | NlpHarnessPipeline | JSON + 验证规则 | confidence, disclosureLevel |
| Step 7 | D2CGenerator | JSON + 模板 | Java代码 + 注解 |
3.2 NLP驱动示例
用户输入
"创建一个用户管理页面,包含用户列表、搜索、新增、编辑、删除功能,字段包括ID、姓名、邮箱、状态"
Step 1: 意图识别
IntentRecognitionResult result = intentRecognizer.recognize(query);
// intent = CREATE_PAGE
// confidence = 0.92
Step 2: 实体提取
ClsEntityResult entityResult = extractor.extract(clsJson);
// moduleName = UserManager
// fields = [id, name, email, status]
// operations = [SEARCH, SAVE, DELETE, ADD, EDIT]
Step 7: 代码生成
@TreeGridViewAnnotation(
dataUrl = "/api/users",
saveUrl = "/api/users/save",
searchUrl = "/api/users/search",
delPath = "/api/users/delete",
columns = {
@Column(field = "id", caption = "ID"),
@Column(field = "name", caption = "姓名"),
@Column(field = "email", caption = "邮箱"),
@Column(field = "status", caption = "状态")
}
)
public class UserManagerView {
// 自动生成的数据绑定和事件处理
}
4. NLP Module Orchestrator
4.1 5步编排流程
NlpModuleOrchestrator作为NLP驱动核心编排器,负责将自然语言转换为结构化UI组件:
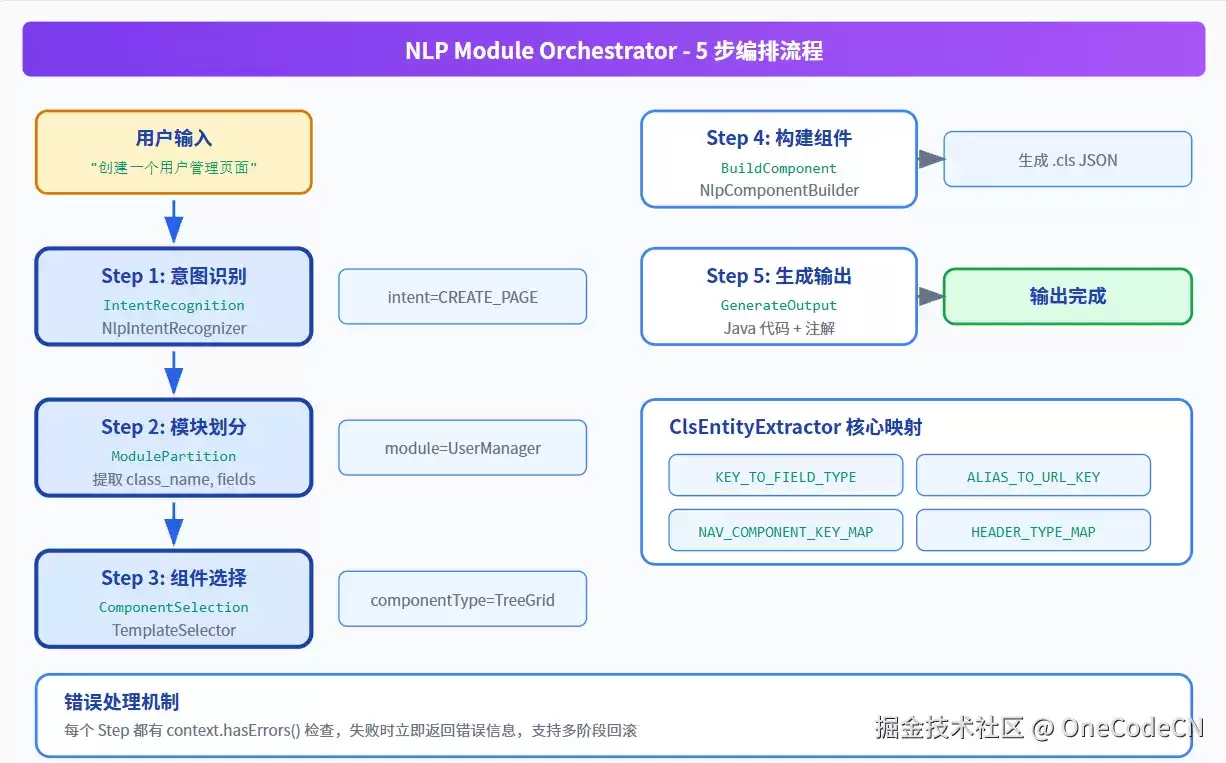
图3:NLP Module Orchestrator-5步编排流程
4.2 核心代码结构
@Service
public class NlpModuleOrchestrator { private final NlpIntentRecognizer intentRecognizer;
private final NlpComponentBuilderFactory componentFactory;
private final TemplateSelector templateSelector; public NlpBuildContext process(String query) {
NlpBuildContext context = new NlpBuildContext(query); context = step1_IntentRecognition(context); // 意图识别
if (context.hasErrors()) return context; context = step2_ModulePartition(context); // 模块划分
if (context.hasErrors()) return context; context = step3_ComponentSelection(context); // 组件选择
if (context.hasErrors()) return context; context = step4_BuildComponent(context); // 构建组件
if (context.hasErrors()) return context; context = step5_GenerateOutput(context); // 生成输出 return context;
}
}
4.3 错误处理机制
每个Step都设有context.hasErrors()检查,失败时立即返回错误信息,支持多阶段回滚。
5. NLP Harness Pipeline
5.1 6阶段管道设计
NlpHarnessPipeline实现了从自然语言输入到构建执行的完整流程,体现了Ooder与传统测试框架的核心差异:
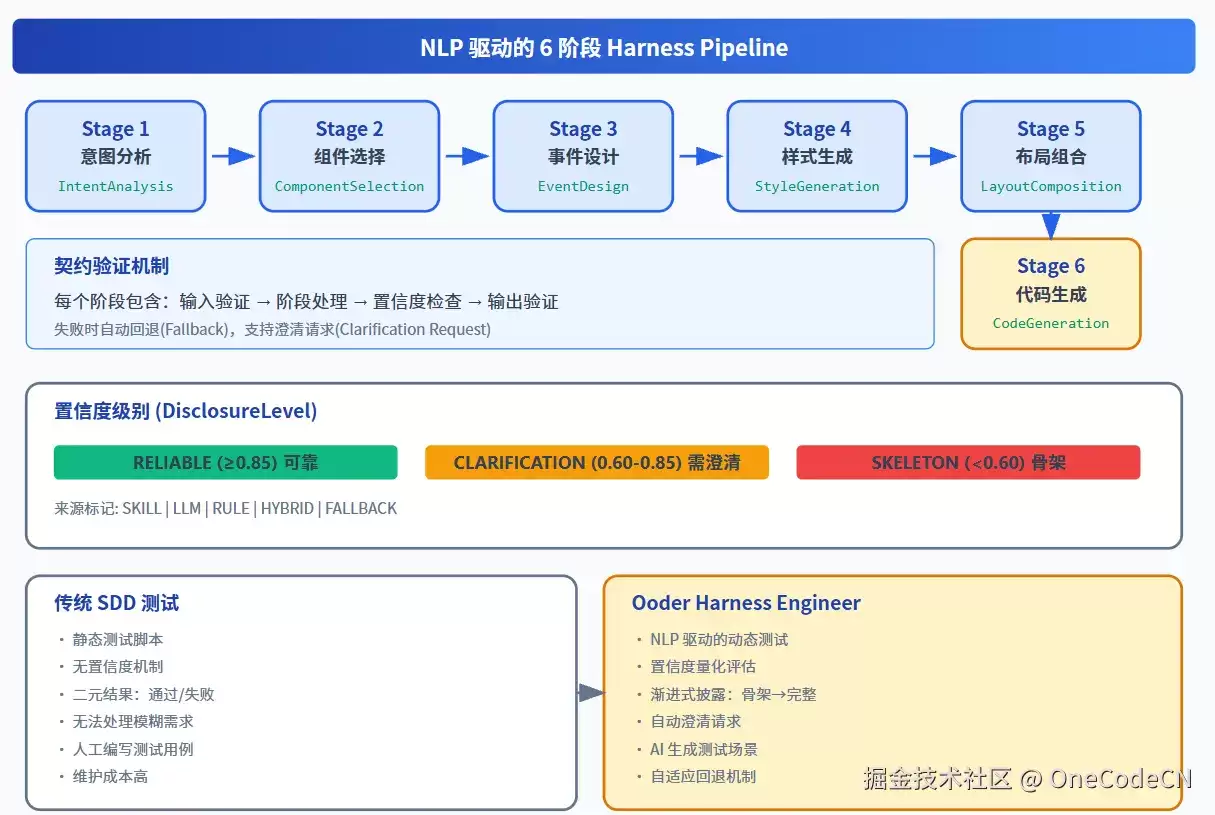
图4:NLP Harness Pipeline-6阶段管道设计
5.2 核心特性:解决"哑巴管道"问题
相比传统测试框架的"输入→处理→输出"哑巴管道模式,Ooder的Harness Engineer使每个处理节点都具备可视化能力:
public class HarnessResult {
private final T data; // 实际数据
private final double confidence; // 置信度0.0-1.0
private final String source; // 来源:SKILL/LLM/RULE/HYBRID/FALLBACK
private final List<String> harnessLog; // 驾驭日志
private final boolean requiresReview; // 是否需要人工复核
private final List<String> suggestions; // 改进建议
}
5.3 置信度级别
| 级别 | 置信度范围 | 含义 | 处理方式 |
|---|---|---|---|
| RELIABLE | ≥0.85 | 可靠 | 直接进入下一阶段 |
| CLARIFICATION | 0.60-0.85 | 需澄清 | 发起澄清请求 |
| SKELETON | <0.60 | 骨架 | 降级处理,生成基础结构 |
5.4 与传统SDD的差异
| 维度 | 传统SDD测试 | Ooder Harness Engineer |
|---|---|---|
| 驱动方式 | 静态测试脚本 | NLP驱动的动态测试 |
| 结果判断 | 二元:通过/失败 | 置信度量化评估 |
| 披露方式 | 全量或无 | 渐进式披露:骨架→完整 |
| 错误处理 | 失败即停止 | 自动澄清请求+自适应回退 |
| 测试生成 | 人工编写 | AI生成测试场景 |
| 维护成本 | 高 | 自适应调整,低维护 |
6. 六维数据空间
6.1 数据流转全景
Ooder定义的六维数据空间,完整描述了NLP驱动下的数据流转过程:

图5:六维数据空间-NLP驱动的数据流转
6.2 各层详解
| 维度 | 名称 | 说明 | 核心类 |
|---|---|---|---|
| D1 | 注解层 | 声明式UI定义 | @FormViewAnnotation, @TreeGridViewAnnotation |
| D2 | Meta层 | 结构化元数据 | CustomViewMeta, CustomFormViewMeta |
| D3 | Properties层 | 四分离模型 | Properties, Styles, Events, Behaviors |
| D4 | .cls JSON层 | 设计时态产物 | 设计器保存格式 |
| D5 | llmMeta层 | LLM可处理格式 | D2CProject.llmMeta |
| D6 | JavaGen层 | 代码生成 | D2CGenerator, GenAnnotationRestoreJava |
6.3 ClsEntityExtractor核心映射
public class ClsEntityExtractor {
// 组件类型映射
private static final Map<String, String> KEY_TO_FIELD_TYPE = new HashMap<>();
static {
KEY_TO_FIELD_TYPE.put("ood.UI.Input", "INPUT");
KEY_TO_FIELD_TYPE.put("ood.UI.ComboInput", "COMBOINPUT");
KEY_TO_FIELD_TYPE.put("ood.UI.DatePicker", "DATEPICKER");
// ... 30+组件映射
} // API别名映射
private static final Map<String, String> ALIAS_TO_URL_KEY = new HashMap<>();
static {
ALIAS_TO_URL_KEY.put("SAVE", "saveUrl");
ALIAS_TO_URL_KEY.put("SEARCH", "searchUrl");
ALIAS_TO_URL_KEY.put("DELETE", "delPath");
// ... 15+API映射
} // 导航组件映射
private static final Map<String, String> NAV_COMPONENT_KEY_MAP = new HashMap<>();
static {
NAV_COMPONENT_KEY_MAP.put("NAVTREECONFIG", "ood.UI.TreeView");
NAV_COMPONENT_KEY_MAP.put("NAVTABSCONFIG", "ood.UI.Tabs");
// ... 10+导航组件映射
}
}
7. 协议层:Agent互联标准化
7.1 四层协议栈
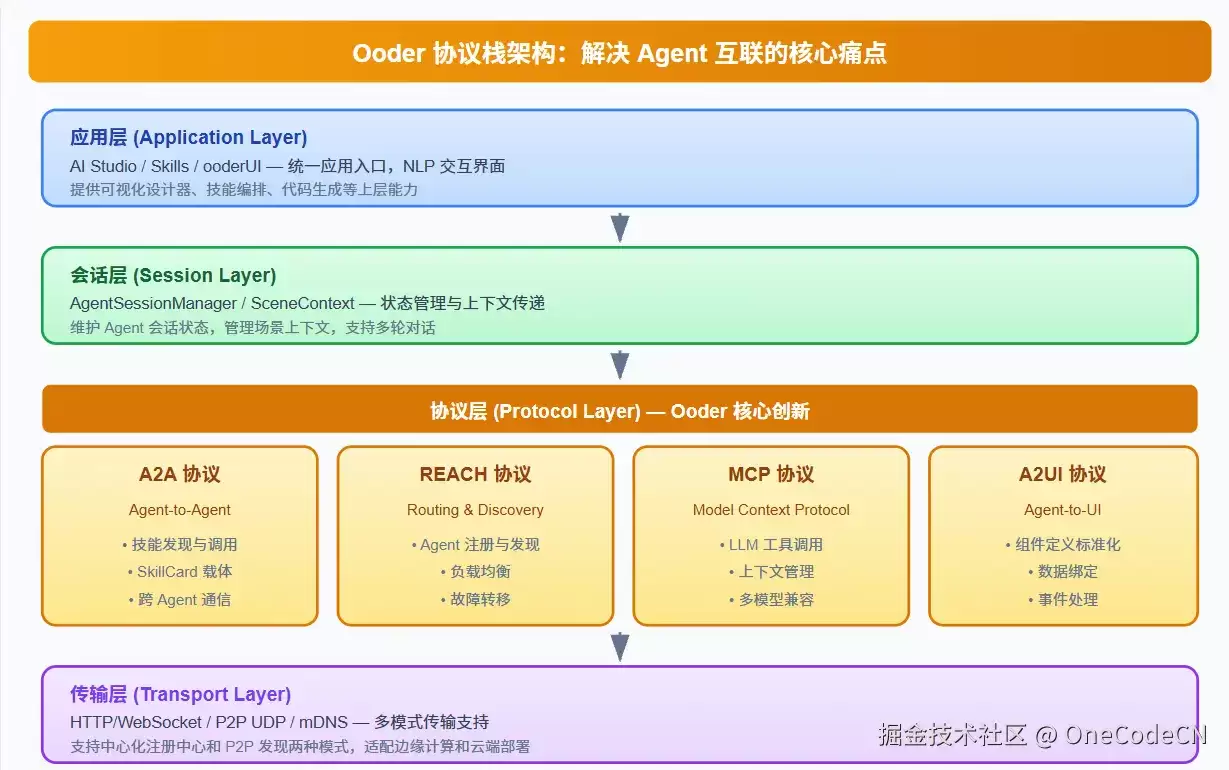
图6:Ooder四层协议栈架构
7.2 A2A协议:Agent互联的基石
SkillCard示例
{
"skillId": "skill-daily-report-001",
"name": "日报生成",
"description": "根据用户输入生成工作日报",
"form": "CHAT",
"sceneType": "DAILY_REPORT",
"purposes": ["效率提升", "文档生成"],
"skillCategory": "SCENE"
}
7.3 REACH协议:动态路由与发现
| 能力 | 说明 | 实现方式 |
|---|---|---|
| Agent注册 | Agent启动时自动注册到网络 | UDP广播+mDNS+注册中心 |
| 服务发现 | 发现网络中可用的Agent和技能 | 主动查询+订阅通知 |
| 负载均衡 | 在多个Agent实例间分配请求 | Random/Weighted/RoundRobin |
| 故障转移 | Agent故障时自动切换到备用实例 | 健康检查+自动摘除 |
8. SDK层:agent-sdk与scene-engine
8.1 agent-sdk架构
agent-sdk 3.0.2架构│├──agent-sdk-core│├──WorkerAgent//工作节点:执行具体任务│├──SceneAgent//场景节点:管理场景上下文│├──EndAgent//终端节点:用户交互入口│├──RouteAgent//路由节点:请求分发│└──McpAgent//MCP协议节点:工具调用│├──llm-sdk│├──StructuredOutputApi//结构化输出│├──ToolCallingApi//工具调用│└──TokenQuotaService//Token配额管理│└──skills-framework├──SkillRegistry//技能注册表├──SkillInstaller//技能安装器└──SkillDiscoverer //技能发现器
8.2 scene-engine:SPI驱动的弹性部署
| 驱动类型 | 存储 | LLM | 向量库 | 包大小 | 适用场景 |
|---|---|---|---|---|---|
| Tiny | 文件 | Ollama | 内存 | <5MB | 开发测试、边缘设备 |
| Small | JDBC | 远程API | Milvus Lite | 15-25MB | 小型部署、POC |
| Enterprise | 分布式 | 多模型路由 | 分布式向量库 | 50-150MB | 企业生产 |
9. Skills架构层
9.1 七层技能设计
| 层级 | 名称 | 职责 | 示例 |
|---|---|---|---|
| Layer 1 | SPI基础层 | 统一接口定义 | StorageProvider, LlmProvider |
| Layer 2 | 驱动层 | 外部系统集成 | DeepSeekDriver, DingTalkDriver |
| Layer 3 | 系统层 | 核心系统服务 | AuthService, ConfigService |
| Layer 4 | 能力层 | 可复用基础能力 | TextGeneration, ImageAnalysis |
| Layer 5 | 场景层 | 业务场景封装 | DailyReport, MeetingScheduler |
| Layer 6 | 业务层 | 业务逻辑处理 | OrderProcess, CustomerService |
| Layer 7 | 工具层 | 辅助工具 | Logger, Metrics |
10. ooderUI全栈方案
10.1 四分离模型
四分离模型将组件数据解耦为四个正交维度:
| 维度 | 说明 | 典型属性 | 解耦收益 |
|---|---|---|---|
| Properties | 业务属性 | dataUrl, saveUrl, searchUrl | 数据驱动,切换后端只需改URL |
| Styles (CS) | 样式配置 | CSS类、主题变量 | 主题系统、设计系统无缝切换 |
| Events | 事件绑定 | onClick, onChange | 交互逻辑模块化 |
| Behaviors | 行为逻辑 | APICaller, Action链 | 复杂交互可配置化 |
10.2 .cls JSON示例