Gemini Omni Demo如何一键生成视频?实战3步搞定
Gemini Omni Demo如何一键生成视频?其实挺简单的,三行对话就搞定。
第一步:打开Gemini App,找到新入口想一键生成视频,先得找到这个模型。根据谷歌官方消息,Gemini Omni已经集成到Gemini应用里,入口就在主页上。点进去之后,界面会提示你“快来认识一下我们全新的视频生成模型”。这里不需要什么复杂的参数设置,对话框就是你的操作台。跟模型说一句“我想看一个教授在黑板上推导数学公式”,它就能直接干活,没错吧?

第二步:用自然语言描述你的视频需求这步才是整个流程的核心——用对话代替鼠标点击。你可以在对话框里写:“一个海边餐厅,夕阳,客人吃意大利面。旁白:'在这一刻,时间像盐一样融化。'”模型会同时生成画面、旁白和环境音,用时据说只要18秒。为什么能这么快?因为Gemini Omni是统一的全能模型,能一次性处理视频、图像、音频和文字。相比之下,以前的Veo还得分开调用,麻烦得很。
第三步:不满意?直接在对话中编辑生成之后要是觉得背景不对,或者角色不满意,直接打字说“把沙滩改成雪地”就行了。模型会重新混剪,连画面风格都跟着变。这种编辑方式挺顺手的,就像跟一个懂视频的助手聊天一样。最终导出时,原生分辨率能支持4K,连续镜头一致性可以保持60秒,这就是谷歌官方资料里提到的能力。
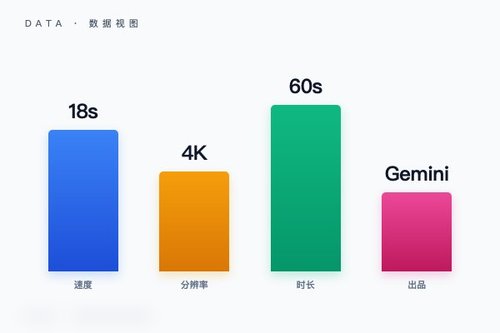
整个流程走下来,无非就是“打开App、描述需求、对话修改”这三步。但有一点得注意:目前这个功能需要订阅Google AI方案或符合要求的Workspace许可,而且未满18周岁的用户暂时无法使用。模型内置了安全机制,对生成真人形象内容比较谨慎,消耗额度也不低——毕竟这种全能模型,算力成本摆在那里。
说到底,Gemini Omni Demo把过去要五个工具串起来才能做的事,重新塞进了同一个对话框。你还得手动调整分镜吗?不用了。你还得单独录旁白吗?也不用。这就是统一模型带来的便利。不过话说回来,目前细节连贯性还有纰漏,官方也承认这一点。所以实战时最好多试几次,挑最顺眼的那段导出。