JuICE基准:评估大模型法官识别文化错误的能力
一篇关于JuICE基准的论文日前正式公开,该基准专门用于评估大模型法官在跨文化场景中识别文化错误的能力。研究团队来自学术界,他们发现当前的大语言模型虽然能输出事实正确的内容,但在特定文化背景下,这些回答可能让本地读者感到“明显不对劲”。JuICE基准正是为了量化这种“文化盲区”而设计的工具。
大模型为何在文化问题上频频“翻车”?
LLM在日常任务中越来越广泛地应用,从起草个人邮件到头脑风暴创意方案,这些场景其实都离不开文化语境。一个回复可能在语法和事实上都无可挑剔,但就是不符合当地的社交习惯或文化符号。问题的关键不在于模型的知识储备,而在于它对文化潜规则的理解能力——这方面,咱们的模型真的还有挺长的路要走。
JuICE基准到底怎么测?
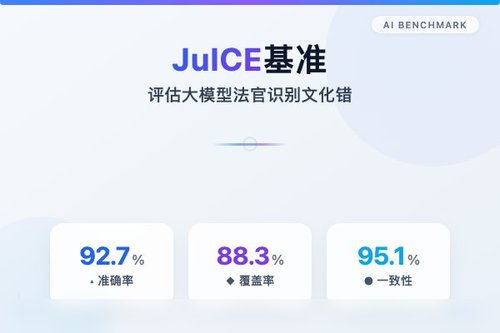
这个基准的核心思路很简单:让大模型作为“法官”,去判断另一个模型生成的回答是否包含文化错误。现有的文化基准大多只关注表面的事实准确性,却忽略了“事实正确但文化错误”这种更隐蔽的问题。JuICE却实实在在地抓住了这个痛点,专门测试模型是否能够识别那些只有本地人才能察觉的尴尬回答,这确实是一个重要的突破。
基准的构建过程可谓相当系统:研究者收集了大量来自不同文化背景的问答案例,这些案例中都包含专业人士标定的文化错误。接着让多个大模型化身“法官”去裁判每个回答。结果很有意思——不少模型在面对自身文化之外的问题时,识别能力大幅下降,有时连明显的“文化雷区”都察觉不到。何来真正的全球化部署能力?现实很残酷:模型可能在美国文化中游刃有余,切换到东亚或中东语境就漏洞百出。
JuICE基准的价值在于它为行业提供了一个可复现的评估标准。过去开发者只能凭感觉调整模型的跨文化表现,现在有了这个基准,大家可以客观地比较不同模型的文化敏感度。这对于追求全球化部署的AI公司来说,可以说是一份非常重要的参照系了。
未来模型的训练和优化需要更多地将文化多样性纳入考量。JuICE基准的提出算是敲响了一记警钟:如果大模型连文化错误都识别不清楚,又怎么指望它们能真正服务于全球用户呢?这确实是一个值得整个行业深思的问题。