Python字典与集合:揭秘它们背后的底层实现原理
作者:袖梨
2026-06-01

当控制台报出unhashable type: 'list'错误时,这个看似简单的提示引发了我对Python字典机制的深入探索。本文将分享从基础原理到实际应用的完整思考过程。
先搞懂:字典为啥比列表快到飞起?
在处理「姓名-成绩」这类数据时,初学者常会使用两个同步列表的低效方案:
# 原始方案:通过下标关联的并行列表
names = ['周杰伦', '蔡徐坤', '周星驰']
score = [100, 2.5, 100]
这种实现存在明显缺陷:查找效率随数据量增长而线性下降。相比之下,字典采用哈希表结构,通过哈希算法将key映射到固定位置,实现O(1)时间复杂度的查询操作:
grades = {'周杰伦': 100, '蔡徐坤': 2.5, '周星驰': 100}
print(grades['蔡徐坤']) # 立即输出2.5
字典的实用技巧包括:
# 1. 修改已有键值
grades['周杰伦'] = 88
# 2. 安全访问方法
print(grades.get('ikun', -1)) # 返回-1而非报错
# 3. 删除操作
grades.pop('蔡徐坤')
核心大坑:为啥列表绝对不能当字典的 key?
哈希表的本质要求key必须保持稳定。可变对象如列表会破坏哈希一致性,导致字典无法正确定位存储位置。允许使用的key类型包括字符串、数字和元组等不可变对象。
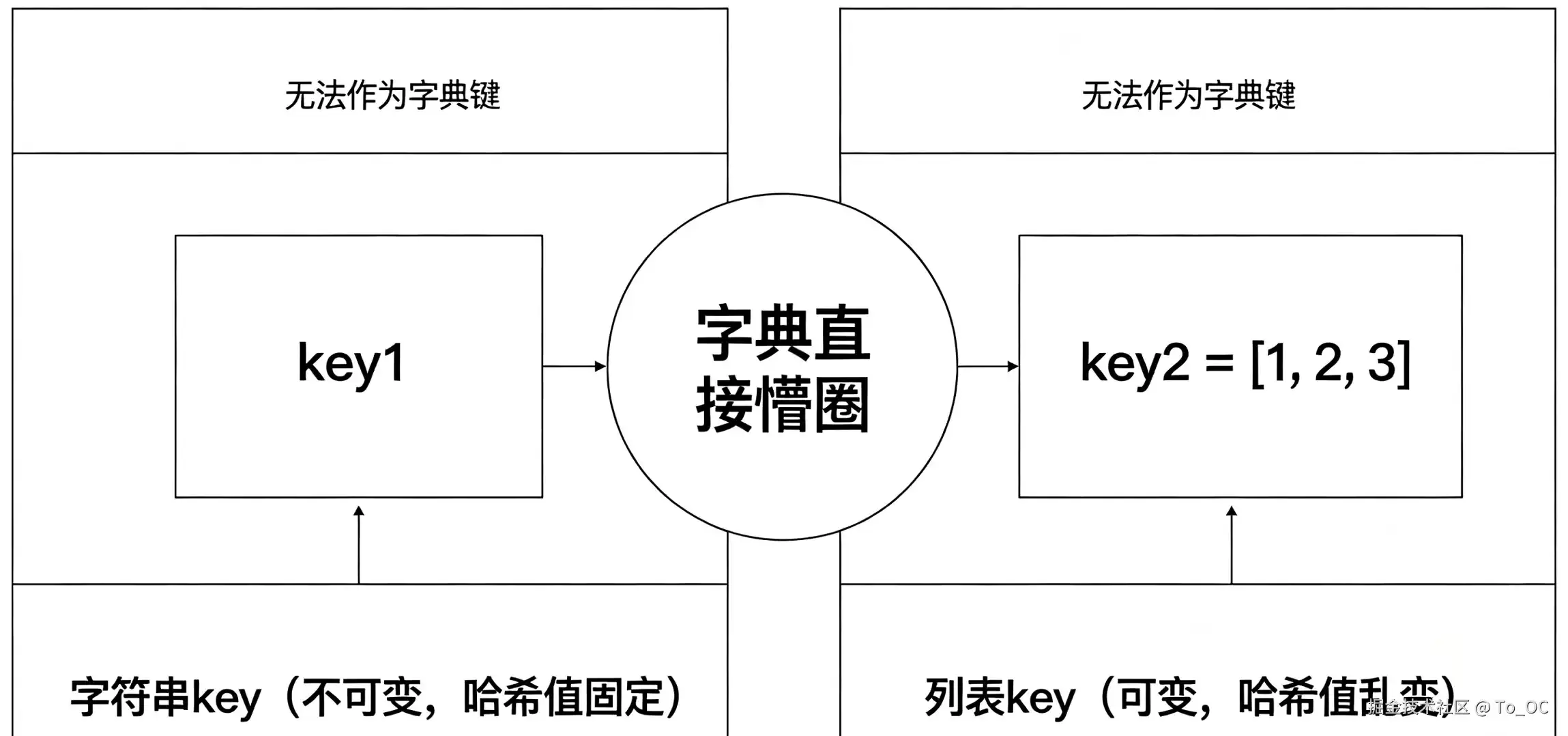
字典的特性可总结为:
- 优势:查询和插入操作的高效性
- 劣势:相对较高的内存消耗
秒懂 Set:就是个没有 value 的字典
集合(set)本质是简化版字典,仅存储key且自动去重。其运算功能在处理数据时尤为实用:
s1 = {1, 2, 3}
s2 = {2, 3, 4}
print(s1 & s2) # 输出交集{2,3}
终极迷惑:可变对象 vs 不可变对象
理解对象可变性对正确使用数据类型至关重要:
# 列表就地修改
lst = [3,1,2]
lst.sort() # 直接修改原对象
# 字符串生成新对象
s = "abc"
s.replace("a","A") # 返回新字符串
通过这次系统性的探索,我们掌握了三个核心要点:字典的哈希机制、数据类型的可变性本质,以及集合的特殊应用场景。这些知识点不仅解决了最初的报错问题,更为后续的Python编程奠定了坚实基础。