快速构建SpringAI项目:实现智能问答-RAG-FUNCTION_CALLING功能集成
作者:袖梨
2026-06-01
Java开发者可通过LangChain4j或SpringAI两种方式构建AI应用,其中SpringAI基于Java17+和SpringBoot3.2+环境,能快速实现功能开发而无需深入底层细节。

-
构建AI聊天机器人全流程指南:
建议先用AI生成前端界面原型,输入需求描述获取最佳提示词方案。后端实现包含本地部署与第三方模型调用两种方案,本示例将同时演示:本地部署采用ollama方案,具体操作可参考官方文档,安装完成后执行以下命令
项目搭建需先引入依赖,注意SpringAI版本更新频繁,部分API可能废弃,本案例使用1.1.3稳定版本<dependency>
<groupId>org.springframework.aigroupId>
<artifactId>spring-ai-bomartifactId>
<version>1.1.3version>
<type>pomtype>
<scope>importscope>
dependency>
<dependency>
<groupId>org.springframework.aigroupId>
<artifactId>spring-ai-advisors-vector-storeartifactId>
dependency>模型配置参数可通过yaml文件管理,包括基础URL、对话模型等核心参数
spring:
application:
name: my-aiProject
ai:
vectorstore:
redis:
enabled: false
ollama:
base-url:
chat:
model: qwen3.5:4b需配置ChatModel、会话记忆存储及系统提示词,当前采用内存存储方案,后续可升级为pgsql/redis/es等持久化方案
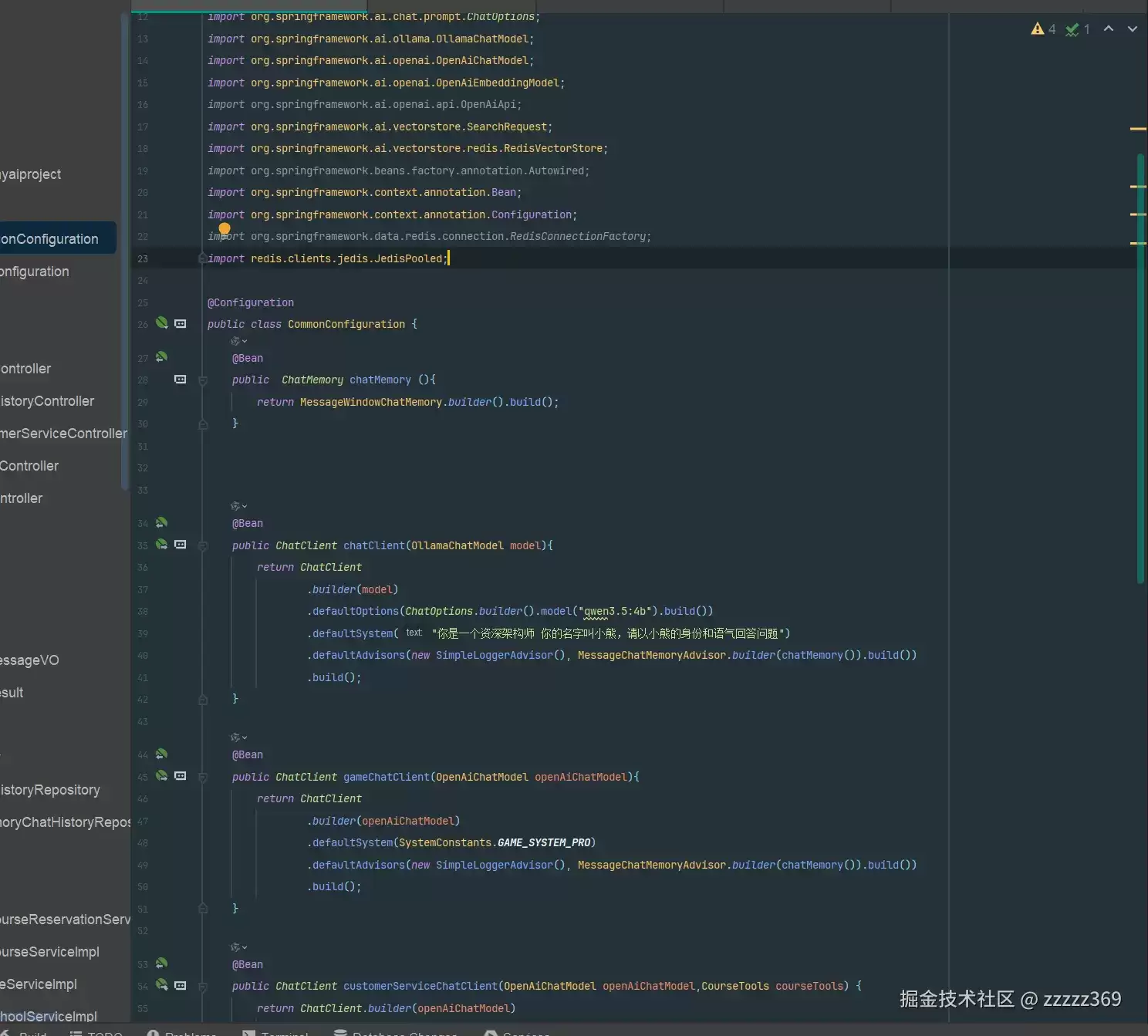
接口开发采用链式编程模式
@RequestMapping(value = "/chat",produces = "text/html;charset=UTF-8")
public Flux chat(@RequestParam("prompt") String prompt,
@RequestParam("chatId") String chatId,
@RequestParam(value = "files",required = false) List files){
chatHistoryRepository.save("chat",chatId);
if (files==null || files.isEmpty()){
return chatClient.prompt()
.advisors(s->s.param(ChatMemory.CONVERSATION_ID,chatId))
.user(prompt)
.stream()
.content();
}else {
return multiModalChat(prompt,chatId,files);
}
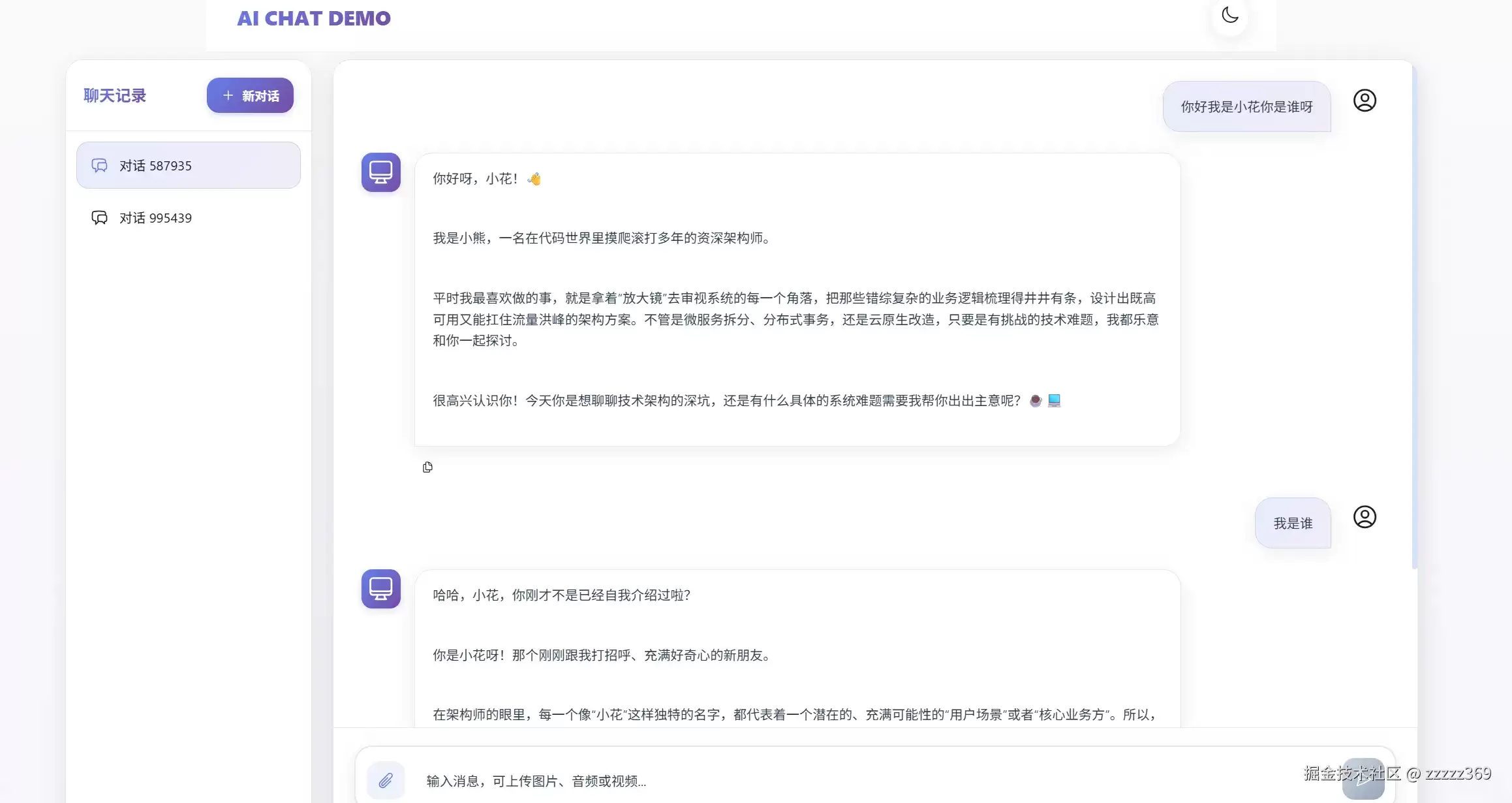
}功能测试结果包含会话记忆验证
RAG+FUNCTION_CALLING集成方案
检索增强生成技术可解决大模型知识时效性与私有数据访问问题,通过本地知识库检索后将真实数据注入模型生成回答
实现分为三个关键步骤: 1. 定义防注入提示词模板 2. 通过defaultTools(courseTools)实现核心功能 3. 配置工具类注解参数
@Bean
public ChatClient customerServiceChatClient(OpenAiChatModel openAiChatModel,CourseTools courseTools) {
return ChatClient.builder(openAiChatModel)
.defaultSystem(SystemConstants.SERVICE_SYSTEM_PROMPT)
.defaultAdvisors(new SimpleLoggerAdvisor(), MessageChatMemoryAdvisor.builder(chatMemory()).build())
.defaultTools(courseTools)
.build();
}自定义Tools需继承Object类并使用SpringAI专用注解
@Component
@RequiredArgsConstructor
public class CourseTools {
@Tool(description = "根据条件查询课程")
public List queryCourse(@ToolParam(description = "查询的条件") CourseQuery courseQuery){
QueryChainWrapper wrapper = courseService.query()
.eq(courseQuery.getType() != null, "type", courseQuery.getType())
.le(courseQuery.getEdu() != null, "edu", courseQuery.getEdu());
return wrapper.list();
}
}@Tool标记AI可调用方法,@ToolParam说明参数用途,实现数据库检索与AI的深度集成
多模态内容处理方案
文本/PDF/图片解析需配合向量数据库,本方案采用redis-stack实现
@Bean
public RedisVectorStore redisVectorStore(OpenAiEmbeddingModel embeddingModel) {
JedisPooled jedisPooled = new JedisPooled("localhost", 32768);
return RedisVectorStore.builder(jedisPooled, embeddingModel)
.indexName("spring-ai-index")
.prefix("spring-ai-")
.metadataFields(
RedisVectorStore.MetadataField.tag("file_name")
)
.initializeSchema(true)
.build();
}注意RedisSearch的TAG字段特殊字符处理,需将"."替换为"_"保证精确匹配
private void writeToVectorStore(Resource resource, String chatId) {
PagePdfDocumentReader reader = new PagePdfDocumentReader(
resource,
PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(ExtractedTextFormatter.defaults())
.withPagesPerDocument(1)
.build()
);
List<Document> documents = reader.read();
String safeFileName = fileName.replace(".", "_");
vectorStore.add(documents);
}PDF解析与企业知识库问答实现方案
public Flux<String> chat(String prompt,String chatId ){
String safeFileName = fileName.replace(".", "_");
return pdfChatClient.prompt()
.advisors(s->s.param(ChatMemory.CONVERSATION_ID,chatId))
.advisors(a->a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION,"file_name == '" + safeFileName + "'"))
.user(prompt)
.stream()
.content();
}本文完整演示了SpringAI项目从环境搭建到多模态处理的开发全流程,虽然相比LangChain4j在多Agent支持方面有所不足,但其简洁的API设计特别适合Java开发者快速实现AI功能集成。