MySQL之B+Tree结构:索引原理与使用优化指南
MySQL索引是提升查询效率的关键组件,本文将深入解析B+Tree结构及其优化策略,帮助开发者掌握索引使用技巧。
索引结构
MySQL数据库系统主要支持四种索引类型,每种类型都有其特定的应用场景和实现方式。
- BTREE索引:作为最常用的索引类型,绝大多数存储引擎都支持B树索引结构
- HASH索引:仅MEMORY引擎提供支持,适用于简单的等值查询场景
- R-tree索引(空间索引):MyISAM引擎特有的索引类型,专为地理空间数据设计,使用频率较低
- Full-text(全文索引):最初仅MyISAM支持,InnoDB从5.6版本开始也实现了全文索引功能
| InnoDB引擎 | MyISAM引擎 | Memory引擎 |
|---|---|---|
| BTREE索引 | 支持 | 支持 |
| HASH索引 | 不支持 | 不支持 |
| R-tree索引 | 不支持 | 支持 |
| Full-text | 5.6版本之后支持 | 支持 |
在数据库领域,当未特别说明索引类型时,通常指的是采用B+树结构组织的索引。这种多路搜索树不一定是严格的二叉树结构。
值得注意的是,聚集索引、复合索引、前缀索引和唯一索引默认都采用B+tree结构,这些索引类型在数据库中统称为索引。
BTREE结构
Btree又称多路平衡树,具有以下m叉树的特性:
- 每个节点最多可包含m个子节点
- 除根节点外,每个节点至少包含[ceil(m/2)]个子节点
- 若根节点不是叶子节点,则必须包含至少两个子节点
- 所有叶子节点都位于同一层级
- 非叶子节点由n个key和n+1个指针组成,其中[ceil(m/2)-1]≤n≤m-1
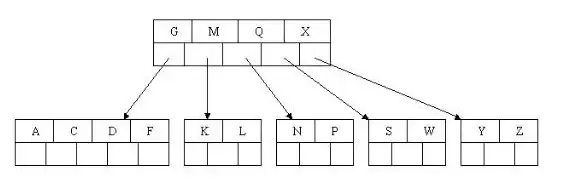
以5叉BTREE为例
插入步骤
在5叉B树中,每个节点的key数量范围为2≤n≤4。当n超过4时,中间节点会分裂到父节点,两侧节点各自分裂。
以插入C N G A H E K Q M F W L T Z D P R X Y S数据为例,具体演变过程如下:
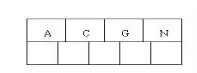
初始阶段,节点空间充足,前4个字母被插入同一节点
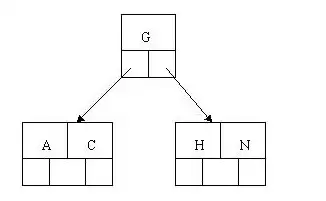
插入H时节点空间不足,中间元素G向上分裂到新节点(ACGHN中G为中间元素)
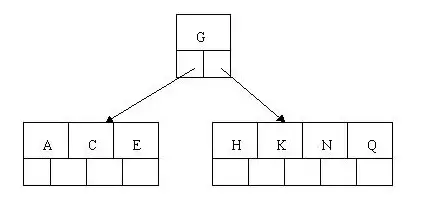
插入E、K、Q时各节点空间充足,无需分裂
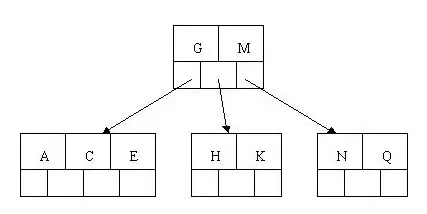
插入M导致HKNQ块分裂,中间元素M上移至父节点G,HK与NQ分别分裂
插入F、W、L、T时节点空间充足,无需分裂
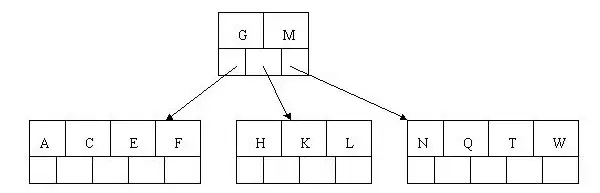
插入Z时,Z大于M走最右指针,在NQTW节点中插入Z后中间元素T上移分裂,NQ和WZ分别分裂
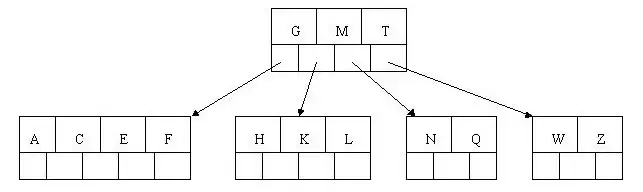
插入D时中间元素D上移分裂,AC和EF分裂,D插入父节点后保持平衡;后续插入P、R、X、Y均满足Btree特性
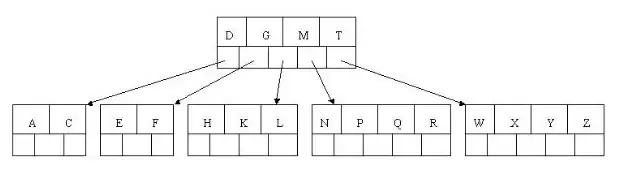
最后插入S时,NPQRS节点key数超限,中间元素Q上移分裂,NP与RS分裂;Q插入父节点DGMT形成DGMQT后再次分裂,中间元素M上移,DG与QT分裂
删除步骤
- 首先定位待删除元素,若存在则删除。删除后若该元素有子节点,则上移相近元素到父节点,然后处理后续情况;若无子节点则直接删除
- 删除后若节点元素数小于ceil(m/2)-1,需检查相邻兄弟节点是否丰满(元素数大于ceil(m/2)-1)。若丰满则向父节点借元素;若兄弟节点也刚满足下限,则合并节点
以下演示删除H、T、R、E的过程:
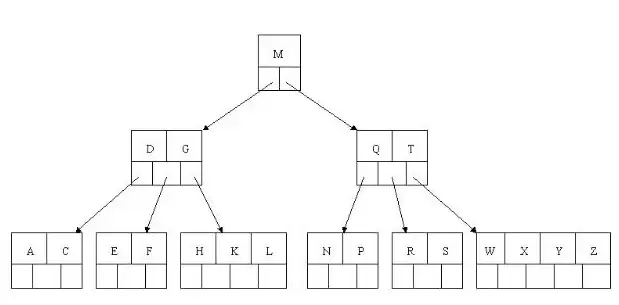
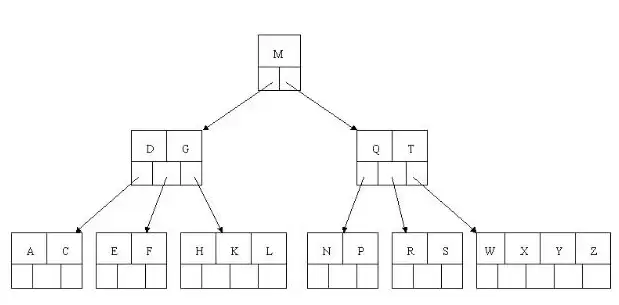
删除H时,该叶子节点元素数3大于最小值2,只需将K移至H位置,L移至K位置

删除T时,找到其后继W上移至T位置,原W所在节点删除W后元素数仍满足条件
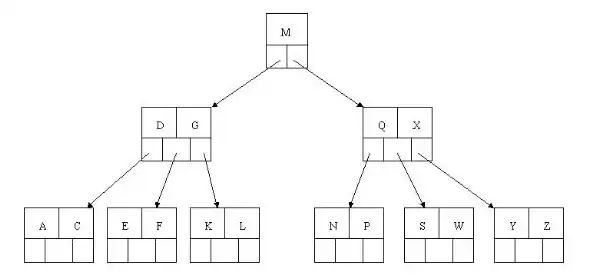
删除R时,叶子节点元素数降为1,向右兄弟借元素W下移替换S,X上移至父节点
删除E时,节点与兄弟节点都刚满足下限,合并节点并将父节点D下移,ACDF合并
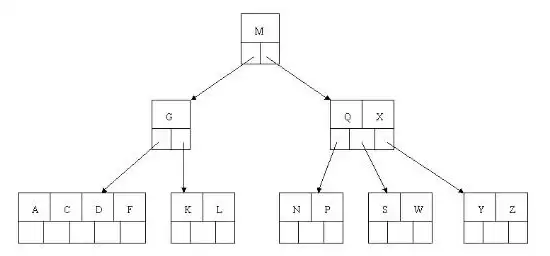
虽然D满足平衡条件,但G节点元素数不足,只能合并节点并将根节点M下移,树高降低
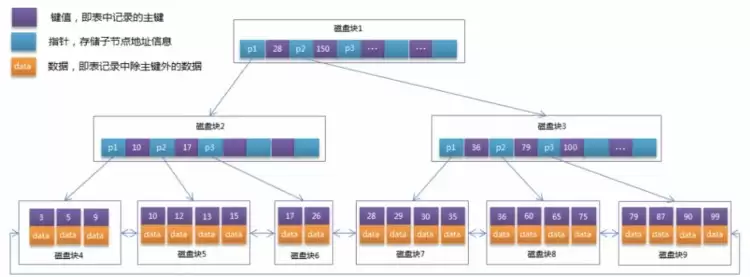
B+TREE结构
B+Tree作为Btree的改进版本,主要区别包括:
- m叉B+Tree最多包含m个key,而Btree最多m-1个
- 所有key信息都存储在叶子节点,并按key大小顺序排列
- 非叶子节点仅作为key的索引部分
由于B+Tree仅在叶子节点存储key信息,查询必须从根节点遍历到叶子节点,因此查询性能更加稳定
MySQL中的B+TREE
MySQL对经典B+Tree进行了优化,增加了指向相邻叶子节点的链表指针,形成带顺序指针的B+Tree,显著提升了区间查询性能
索引分类
- 单值索引(单列索引):仅包含单个列的索引,一个表可创建多个单列索引
- 唯一索引:索引列值必须唯一,但允许存在NULL值
- 复合索引:包含多个列的索引结构
索引语法
创建索引
-- 创建索引的时候不指定索引的类型的时候默认使用的是B+TREE索引 -- 方式一:使用create的方式创建索引 create [UNIQUE|FULL TEXT|SPATIAL] INDEX index_name [USING index_type] on table_name(index_col_name,...); -- 方式二:使用alter方式创建索引 -- 普通的索引 alter table table_name add index index_name(columnName_list); -- 唯一索引(索引的列里面的值除了null可以多次出现,其余的值必须唯一) alter table table_name add unique index index_name(columnName_list); -- 全文索引 alter table table_name add fulltext index_name(columnName_list);
查看索引
show index from table_name;
删除索引
drop index index_name on table_name;
索引失效情形
定义了索引而索引失效的分析
情形一:对索引字段在条件查询中使用函数
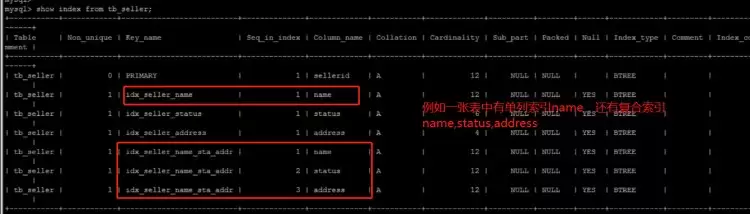
情形二:以name,status,address复合索引为例:
- 等值查询
where name = 'aa' and status ='1' and address = '苏州市'全部走索引 - 范围查询
where name = 'aa' and status >'1' and address = '苏州市'只有name和status走索引 - 等值查询
where name = 'aa' and address = '苏州市'仅name走索引 - 等值查询
where address = '苏州市'不走索引 - 等值查询
where status = '1' and address = '苏州市' and name = 'aa'全部走索引 - 等值查询
where name = 'aa'走name索引
情形三:上述案例中where name = 'aa' and status = 1仅name走索引,status因隐式转换失效
情形四:使用or关联条件时,若or后字段无索引,则整个查询不走索引
select name,status,address where name = 'aa' or remark = 'bb';-- 索引失效 select name,status,address where name = 'aa' and remark = 'bb';-- name走索引
- 模糊查询以%开头不走索引,%结尾可走索引,可使用覆盖索引解决
-- 使用覆盖索引即使%开头仍走索引 select id,name,status,address where name like '%aa%';
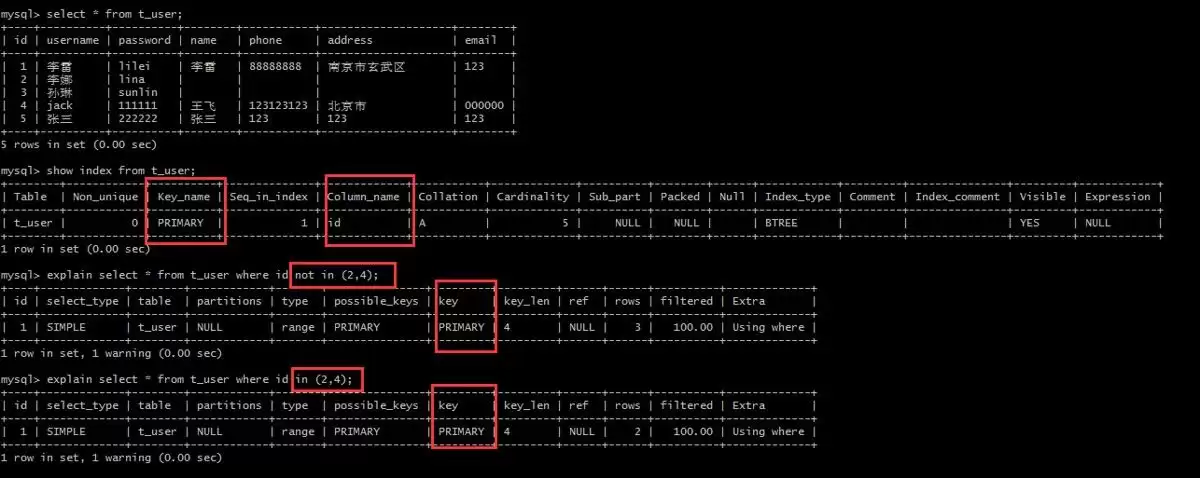
MySQL8.0前使用in走索引而not in不走,8.0后两者都走索引
5.7版本执行情况:
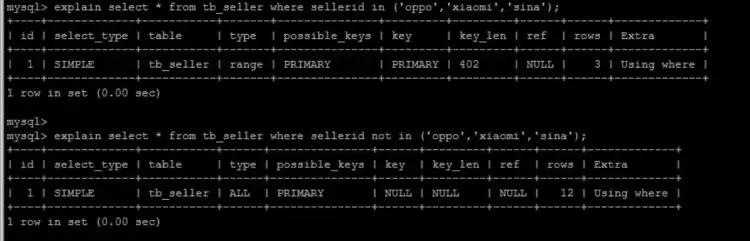
8版本执行情况:
情形五:MySQL评估使用索引比全表更慢时,自动选择全表扫描
当索引字段值分布过于集中(如'北京市'占比过高),执行select * from seller where name = '北京市';会走全表扫描
而select * from seller where name = '西安市';则正常走索引

情形六:is null和is not null是否走索引取决于数据分布
当字段NULL值占多数时,is null不走索引而is not null走;反之亦然
name字段索引情况:

is null查询:
is not null查询:

SQL优化的细节
- 合理使用索引并结合explain分析执行计划
- 查询时尽量使用覆盖索引,避免回表操作
select * from table_name where name= 'aa';-- 需要回表 select name,status,address from table_name where name= 'aa';-- 覆盖索引 select name,status,remark from table_name where name = 'aa';-- 需要回表
大批量导入数据
使用load指令导入数据时:
- 数据最好按主键顺序排列
load data local infile 'filepath' into table `table_name` fields terminated ',' line terminated 'n';
- 关闭唯一性校验提升导入速度
set UNIQUE_CHECKS=0;-- 导入前关闭 set UNIQUE_CHECKS=1;-- 导入后开启
- 采用手动提交事务模式
insert时候优化的细节
批量插入时合并SQL语句,开启手动事务,确保插入数据主键有序
order by排序的时候
explain的extra显示using index表示使用索引排序,Using filesort表示未使用索引
emp表age和salary复合索引示例:
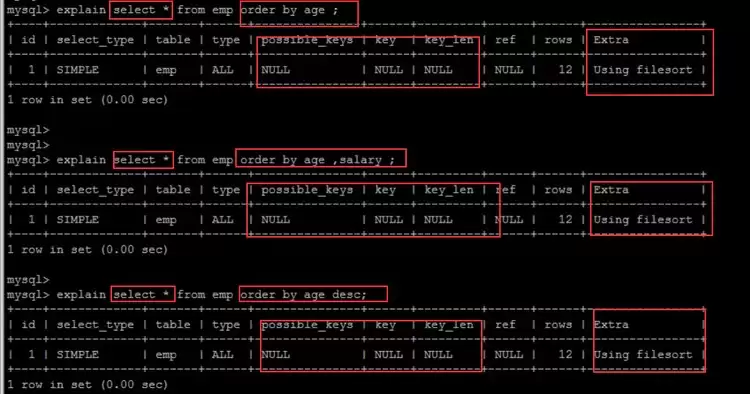
使用覆盖索引且排序字段顺序与索引一致时走索引,否则出现filesort
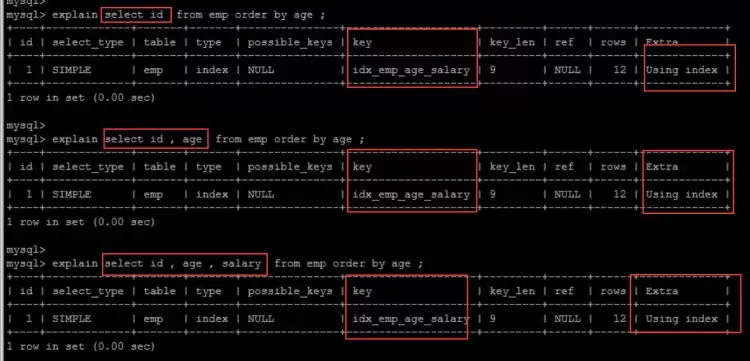
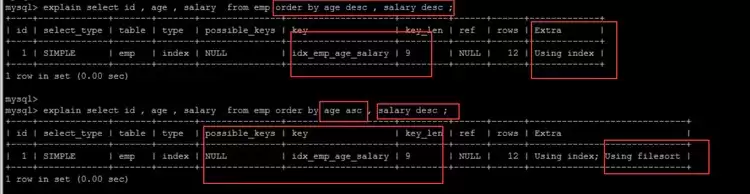

对出现filesort的优化
MySQL有两种排序算法:
1)两次扫描算法:先取排序字段和行指针排序,再回表读取记录,可能产生大量随机I/O
2)一次扫描算法:一次性取出所有字段排序后直接输出,效率更高但内存消耗大
通过调整max_length_for_sort_data和sort_buffer_size参数可优化排序性能
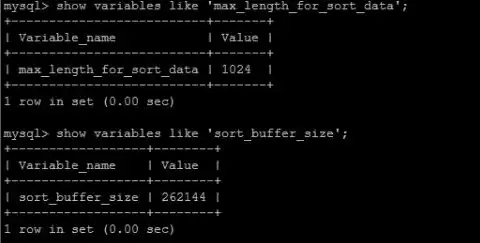
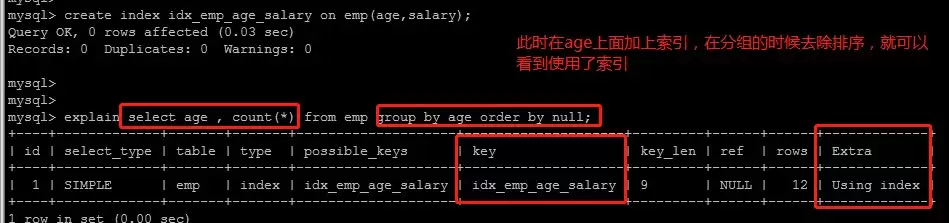
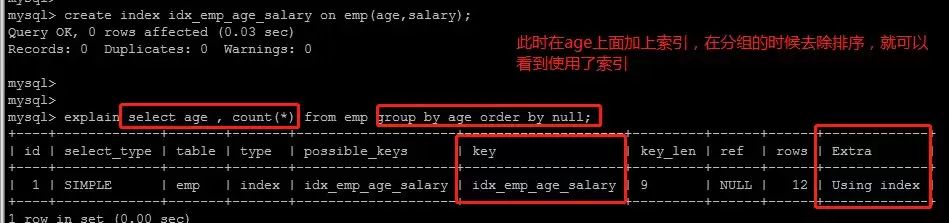
group by语句的优化
GROUP BY隐含排序操作,可通过order by null禁用排序
Using temporary表示使用了临时表
子查询优化
某些情况下使用JOIN替代子查询可获得更好性能
or优化
当or前后字段索引情况不一致时,建议使用union替代
复合索引idx_age_salary示例:
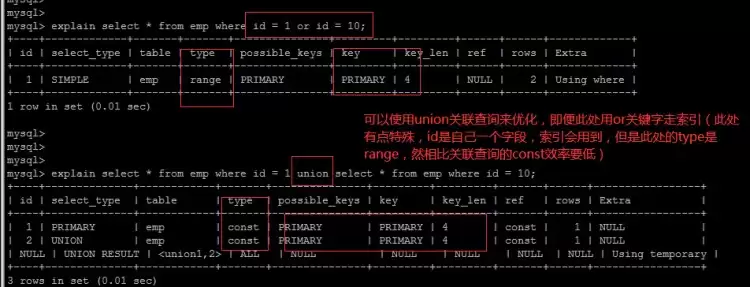
使用union后查询类型优化为const和ref

limit分页查询优化
优化方案一:先排序主键再关联查询
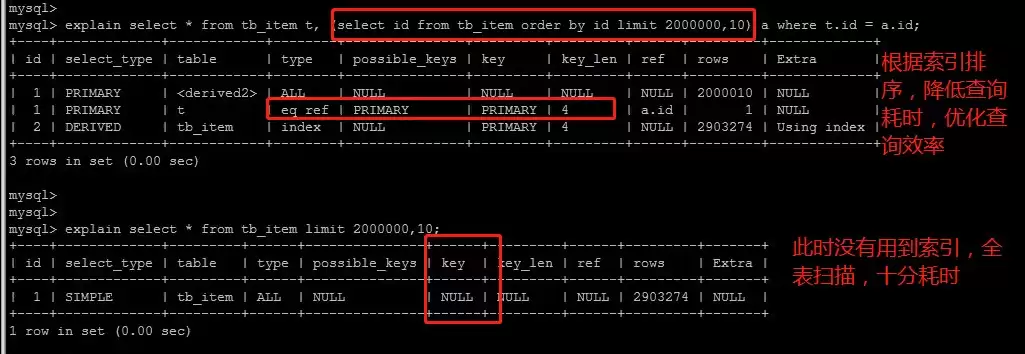
优化方案二:适用于ID连续的表,转换为位置查询
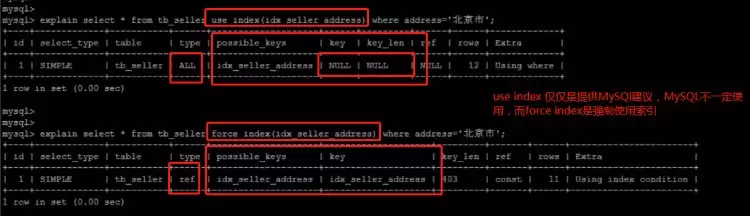
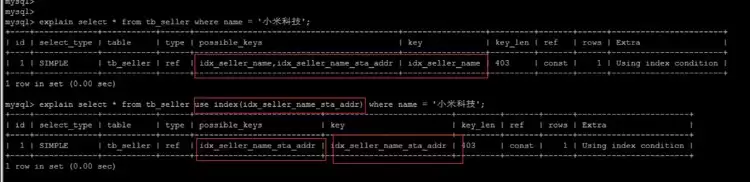
索引提示
use index建议MySQL去使用哪个
人为指定参考索引,MySQL不一定采纳
强制使用指定索引:
ignore index忽略索引
忽略特定索引:
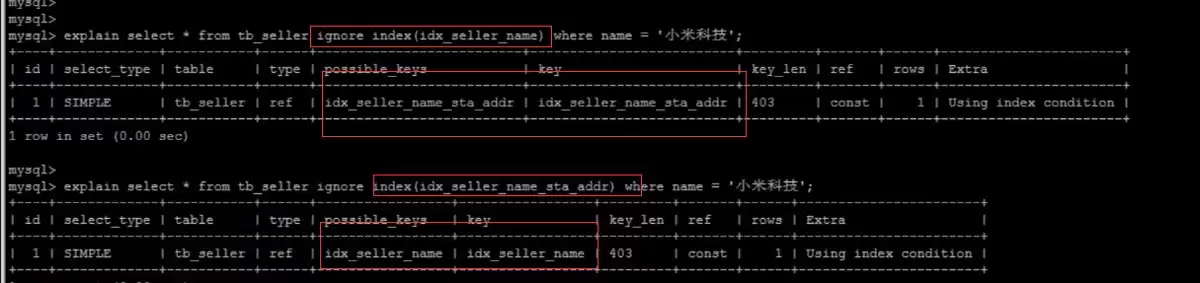
froce index强制使用某个索引
当MySQL选择全表扫描时强制使用索引

使用force index后:
总结
本文详细解析了MySQL索引原理及优化策略,掌握这些技巧能显著提升数据库查询性能,建议开发者结合实际场景灵活应用。