Libra 高效管理 Agentic RL 后训练中的长尾非稳态资源
Libra 系统正式亮相:专为 Agentic RL 后训练中的资源管理难题而生
日前,一篇题为《Libra: Efficient Resource Management for Agentic RL Post-Training》的论文在 arXiv 上发布。论文核心指向了强化学习(RL)在大语言模型(LLM)后训练阶段中遇到的一个棘手问题——当模型开始玩转多轮智能体行为(Agentic RL)时,其资源消耗变得又长又飘忽,传统管理手段根本跟不上。
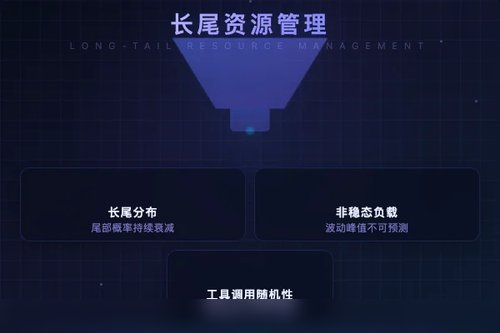
所谓“长尾非稳态”到底是个啥?
说白了,Agentic RL 在生成推理轨迹(rollout)时会调用各种工具,比如数据库查询、代码执行等等。这就导致一个现象:大部分任务跑得挺快,但总有那么一小撮任务耗时极长,就像快递站里总有几个特别难送的包裹一样。论文一针见血地指出,这种长尾分布会严重拖慢整体 rollout 完成时间。你可能会问,这不是靠加算力就能解决的吗?传统资源管理方法偏偏对这类动态变化的非稳态负载毫无办法,它们本质上默认负载是“平稳”的。
三大核心挑战,一个比一个头疼
论文梳理了三个绕不开的坎儿:
- 长尾分布让极少数轨迹绑架了整体流程,资源被低效占用。
- rollout 和后续的优化阶段相互牵扯,即便加了新机器也得花大力气重新平衡。
- 工具调用的随机性让资源需求一直在变,预分配方案根本猜不准。
这就不难理解为什么大家觉得后训练阶段特别费钱又费时了——任务没结束,GPU 就得一直等着那些拖拉的轨迹,算力浪费得很。Libra 系统的价值就在这里:它不是简单加机器,而是通过算法去“管理”这种不稳定。论文虽然没有公布具体测试数据,但其解决问题的方向——把长尾资源消耗作为第一性原理来对待——确实很对味儿。
Libra 的出现或许能给行业降降温
目前不少团队在跑 Agentic RL 后训练时都遇到过类似瓶颈,有人直接堆几百块卡死扛,有人干脆放弃复杂多轮任务。Libra 这个方案,起码让大家知道这事有解法——关键是思路得换,别再拿老一套去套动态负载。这算是给整个 AI 行业提了个醒:智能体的训练从来不该是烧钱游戏,高效管理才是真本事。