实测Gemini Omni 使用教程:6步生成第一个AI视频
Gemini Omni是谷歌在2026年I/O大会发布的全模态模型,视频生成只是它的能力之一。想用它做出第一个AI视频?其实只需要6步:订阅、访问、写提示词、生成、微调、导出。这篇使用教程会带你一步步完成,整个过程挺简单,说白了就是把过去要五个工具串起来的事,现在一个模型就搞定了。
第1步:订阅服务
想用Omni,得先有个谷歌账号。目前AI Plus、Pro和Ultra订阅用户都能使用,实测中Ultra会员体验最完整。订阅后就能通过Gemini应用或谷歌AI视频创作平台Flow来访问,准备工作这就完成了。
第2-3步:访问平台并写下创意
打开Flow或Gemini,新建一个对话。你可能会问:提示词该怎么写?其实不用太复杂,像"一个海边餐厅,夕阳,客人吃意大利面。旁白:'在这一刻,时间像盐一样融化。'"这样一句话,模型就能理解。它会把脚本、画面、旁白、配乐一并生成,确实方便。官方demo里还有教授在黑板上推公式的案例,连贯性和一致性都让人印象深刻。
第4-5步:生成并微调视频
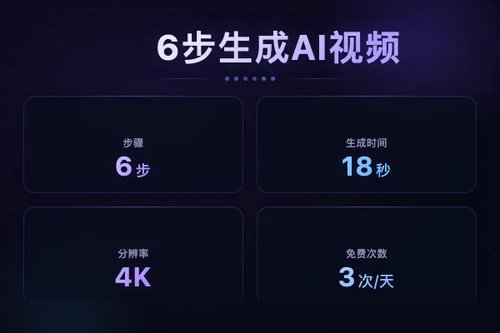
点击生成后,等待约18秒,一个4K分辨率的视频就出来了。官方数据显示它能保持60秒连续镜头一致性,支持40多种语言的旁白。如果对结果不满意,直接用自然语言告诉它怎么改就行,多轮编辑后一致性依然能保持。从实际测试来看,前后一致性基本到位。
第6步:预览并导出成品
微调完成后,预览确认没问题就可以导出了。整个流程下来,真的不用什么专业技能。不过实测也发现,Omni目前表现"有点拉"——这是来自AI新榜的一手评价,说明它还有提升空间。但作为第一个全模态模型,这个起点确实挺高的,毕竟能同时处理文本、图像、音频、视频输入输出的模型,市面上确实不多。
从教授黑板推公式到一句话编辑视频,Gemini Omni让视频生成的门槛降了不少。每天还有3次免费生成机会(无需信用卡),想尝鲜的话现在就能试试。说到底,AI视频工具已经从"能不能做"进化到了"做得好不好"的阶段,Omni算是交了一份不错的答卷,不是吗?