Agent-Orchestrated自适应RAG对比结构化与多跳检索
Agent-Orchestrated自适应RAG框架发布,动态检索策略击败传统单步方案
一项由研究团队在arXiv上发布的最新工作(编号:2606.05658v1)直接回答了当前RAG(检索增强生成,即让大模型在回答前先去外部知识库找资料的技术)领域的核心问题:面对复杂查询时,静态的、一次性检索方式为何表现不佳,以及如何用智能代理驱动的自适应流程来替代它。该研究提出的Agent-Orchestrated自适应RAG框架,通过将复杂问题动态分解、多次迭代检索,并引入自我反思的评估环节,在两项不同的数据集上都取得了更优的结果。
传统RAG管线的局限性在于,它对所有问题都执行“一次性检索”,遇到需要推理多个步骤或整合不同来源信息的提问时,常常遗漏关键证据。例如,用户问“如何修复昨天提到的Kubernetes集群中Pod启动失败的问题”,系统可能只搜索到“Pod启动失败”的通用文档,而忽略“昨天集群更新”这一上下文。新框架的核心改进,是将检索过程变成一个由智能代理(Agent)编排的、能自我纠错的循环。
框架的核心机制:动态分解与自我反思

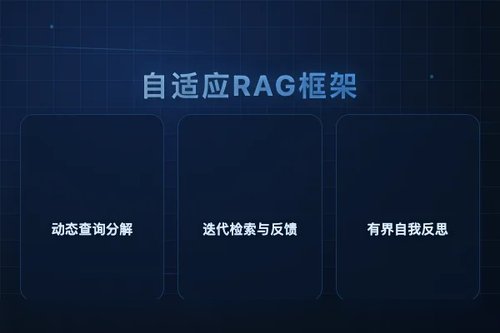
这套Agent-Orchestrated架构主要由三个步骤构成:
- 动态查询分解:代理在收到问题后,会评估其复杂度,并将复合问题拆解为若干子查询。例如,“对比结构化RAG与多跳检索的优缺点”会被拆分为“什么是结构化RAG”和“什么是多跳检索”两个子任务。
- 迭代检索与反馈:每次检索到部分信息后,代理会判断这些信息是否足以回答原始问题。如果不足,它会基于已获得的信息生成新的搜索查询,继续检索,直到信息完整或达到预设轮次上限。
- 有界自我反思评估:系统在生成最终答案前,会进入一个受约束的自我检查环节,确保检索到的内容与问题匹配,避免“答非所问”的幻觉。
实验验证:在专业与推理两个维度表现突出
研究团队在两种类型的知识库上进行了验证。第一个数据集是特定领域的DevOps(开发运维一体化)知识库,包含大量技术文档、配置错误和故障排查案例,用于评估系统在专业细节上的检索精确度。第二个数据集是多跳推理基准测试,专门设计来考察模型连接分散信息、进行逻辑链推理的能力。
初步结果显示,相比传统的结构化检索(按固定索引架构搜索)和多跳检索(依赖模型自身推理能力),Agent-Orchestrated框架在两种场景下均能更有效地定位到正确答案。在DevOps场景中,它减少了检索到无关文档导致的错误答案;在多跳推理任务中,它通过主动分解和补充检索,弥补了模型自身推理链中可能断裂的环节。
对AI应用落地的意义
这一研究对于想把LLM(大语言模型)真正用起来的开发者来说很直接:不再需要为复杂查询手动设计复杂的检索流水线。通过给模型一个“会自己找资料并反思”的智能代理框架,可以让它在客服、技术文档问答、企业知识管理这些场景中完成更复杂的信息整合任务。该工作并非提供某个最终产品,而是给出了一个经过对比验证的可行架构方案。
目前该论文已在arXiv上公开,研究团队也在论文中详细列出了实验设置和基准对比数据。对于从事RAG系统优化或AI应用开发的团队而言,这套“先分解、再迭代、最后自检”的检索策略,提供了一条区别于简单向量检索或单一模型推理的实践路径。