Google DeepMind 推出 Gemma 4 26B 多模态量化对话模型
Google DeepMind 推出 Gemma 4 26B 多模态量化对话模型
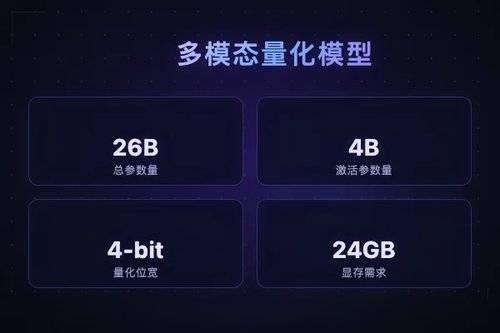
Google DeepMind 日前在 Hugging Face 平台发布了最新的 Gemma 4 系列模型:google/gemma-4-26B-A4B-it-qat-q4_0-unquantized-assistant。这是一款支持图像与文本输入的多模态对话模型,采用量化感知训练(QAT)技术,模型参数量为 26B,但通过混合专家架构(MoE)实现了仅激活 4B 参数的高效推理。该模型基于 Apache-2.0 开源协议发布,开发者可以直接用于文本生成、图文理解和对话系统等场景。
模型核心特点与架构
Gemma 4 系列延续了 Google 轻量化开源模型路线。此次发布的版本属于指令微调后的对话模型(it 版本),并叠加了助理优化(assistant)。其最大特点是采用 QAT 量化方案,在训练阶段就模拟低精度运算,使得最终模型在部署时能保持较高准确率。从 Hugging Face 标签可以看到,该模型兼容 Transformers 框架,支持 safetensors 格式,并且被标记为“image-text-to-text”,意味着它能同时处理图片和文字信息,适用于视觉问答、图文理解等任务。
量化与性能平衡
模型名称中的“q4_0”代表 4-bit 量化,大幅降低了显存占用。对于一张 24GB 显存的消费级显卡(如 RTX 4090),可以直接运行该模型进行本地推理。量化版本在减少模型体积的同时,通过 QAT 技术弥补了精度损失。未量化版本(unquantized)则保留了完整精度,适合企业级服务器部署。开发者可以根据硬件条件在性能与资源占用之间灵活选择。
获取与使用方式
该模型目前已在 Hugging Face 平台上线,模型 ID 为 google/gemma-4-26B-A4B-it-qat-q4_0-unquantized-assistant。用户可以:
- 直接通过 Transformers 库加载模型,调用文本生成或图文理解接口
- 利用 safetensors 格式进行安全高效的权重加载
- 基于 Apache-2.0 许可进行二次开发或商用
截至发布时,模型页面显示有 62 次下载和 2 个点赞,社区关注度正在提升。
开源生态与部署建议
Gemma 4 采用 Apache-2.0 许可证,这意味着企业和个人开发者可以自由使用、修改和分发模型。对于需要私有化部署的场景,量化版本是比较经济的方案——仅需 4B 参数的计算开销即可调用 26B 参数的模型能力。Google DeepMind 还提供了 base_model 和 finetune 信息,方便开发者在此基础上进行领域微调。
从技术演进来看,量化多模态模型的发布正在降低 AI 应用的门槛。开发者不再需要昂贵的多卡集群,一张中高端显卡就能运行具备视觉理解能力的对话模型。这对于中小企业、独立开发者和研究机构来说,是一个值得尝试的开源选项。