正则表达式的整理与归纳:附例子
作者:袖梨
2026-06-07
正则表达式是由普通字符(a-z)和特殊字符(元字符)组成的文本模式。例如,在正则表达式“[a-z]*”描述了所有仅包含小写字母的字符串,其中a,z为普通字符,连字符、左右中括号及星号则为元字符
正则表达式中的元字符的类别
1. 点号
点号可以匹配除“n”之外的任何单字符 。
2. 中括号
可以在中括号([])内指定需要匹配的若干字符,表示仅使用这些字符参与匹配。
3. 竖线
竖线(|)可以匹配其左侧或右侧的符号。
4. ^符号
^符号可以匹配一行的开始。
5. 美元符号
美元符号($)可以匹配一行的结束。
6. 反斜线
反斜线()表示其后的字符是普通字符而非元字符。
常用的匹配次数元符号
| 元字符 | 含义 |
|---|---|
| X* | 匹配X出现零次或多次,如Y、YXXXY |
| X+ | 匹配X出现一次或多次,如YXY、YXX |
| X? | 匹配X出现零次或一次,如Y、YXY |
| X{n} | 匹配X恰好出现n次 |
| X{n,} | 匹配X出现至少n次 |
| X{n,m} | n<=m,匹配X出现至少n次,最多m次 |
预定义字符(只匹配一个字符)
| 元字符 | 含义 |
|---|---|
| d | 数字,相当于[0-9] |
| D | 非数字,相当于[^0-9] |
| s | 空白字符,相当于[tnx0Bfr] |
| S | 非空白字符,相当于[^s] |
| w | 单词字符,相当于[a-zA-Z_0-9] |
| W | 非单词字符,相当于[^w] |
| b | 单词边界 |
| B | 非单词边界 |
| A | 输入的开头 |
| G | 上一个匹配的结尾 |
自定义字符(只匹配一个字符)
| 元字符 | 含义 |
|---|---|
| [abc] | 只能是a,b或c |
| [^abc] | 除了a,b,c之外的任何字符 |
| [a-zA-Z] | a到z A到Z,包括(范围) |
| [a-d[m-p]] | a到d,或m到p |
| [a-z&&[bcd]] | a-z和bcd的交集,为b,c,d |
| [a-z&&[^bcd]] | a-z和非bcd的交集,等同于[ae-z] |
| [a-z&&[^m-p]] | a-z和除了m到p的交集,等同于[a-lq-z] |
举例如下
import java.util.ArrayList;import java.util.List;//通过正则表达式来提取访问数据中的人物姓名并进行去重public class MyMain { public static void main(String[] args) { String log = "张三10:23:0:802023-10-09 09:21:22" + "李四115:203:10:1802023-05-09 19:21:22" + "王五115:203:10:1802023-05-09 19:21:22" + "张三11:22:0:802024-11-09 07:21:25"; // 解析出姓名并写入到List String[] nameIPs = log.split("d{4}-d{2}-d{2} d{2}:d{2}:d{2}"); // 该List中的姓名可能会出现重复 List<String> names = new ArrayList<String>(); for(String nameIP : nameIPs) { int index = -1; //找到第一个数字的地址,结束内层循环 for (int i = 0; i < nameIP.length(); i++) { if(nameIP.charAt(i) >= '0' && nameIP.charAt(i) <= '9') { index = i; break; } } // 内层for //截取名字部分,即从零到第一个数字的部分 String name = nameIP.substring(0, index); //向集合之中添加该名字 names.add(name); } // 对List中的姓名去重 // 该List中的姓名是唯一的 //定义一个新的集合,用来存放不重复的名字 List<String> nameUniques = new ArrayList<String>(); for(String name : names) { if(!nameUniques.contains(name)) { nameUniques.add(name); } } for(String name : nameUniques) { System.out.println(name); } }}运行结果
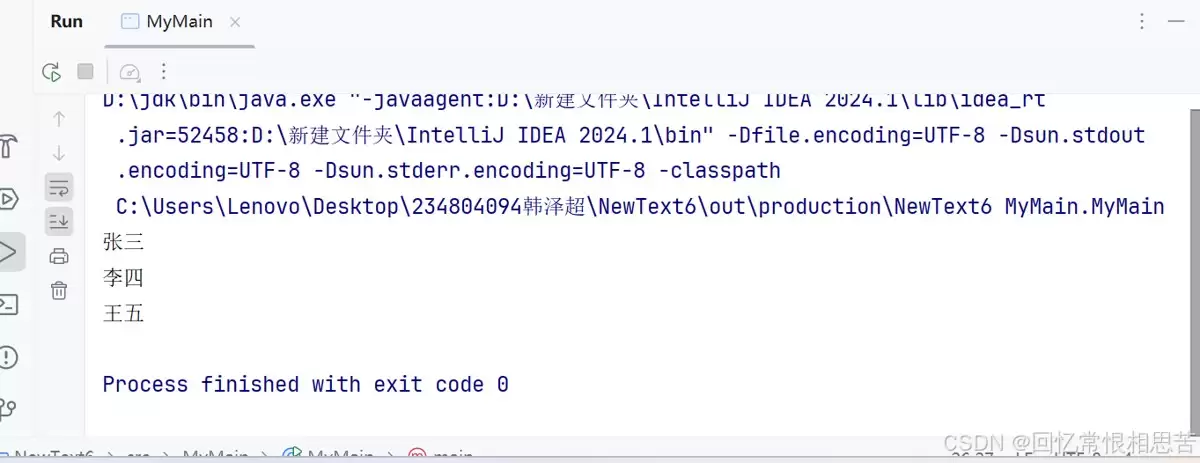
其它方面的细节及注意事项
- 为转义字符,用于改变后面那个字符原本的含义,在程序中d才表示一个d的含义。
- 正则表达式是从左到右一个一个去匹配的,一个表达式只对应一个字符。
- matches()方法可以用于判断一个字符串是否满足对应的正则表达式,并返回结果true或者false。
- 如果要求两个范围的交集,需要写符号&&,若只写一个&,则只表示一个&符号。