kingbase备份与恢复实战(七)—— 恢复演练与验收:从能恢复到可交付预案
引言
备份这活儿,就算你平时做得再勤快,要是不去做“演练和验收”的话,很多时候往往仅仅只是个心理安慰罢了:
- 事故发生之后,怎么去判断到底要用啥恢复策略
- 恢复操作具体该怎么执行(也就是谁来做、大概做多久)
- 恢复完了之后怎么去验收(啥叫“恢复成功”得定清楚)
要是失败了的话该咋回滚或者重新来过(这些在预案里面得写得清清楚楚的),这篇文章是《备份与复原实战》系列的最后一篇,那么我会直接给大伙拿出一套“拿来就能用”的模板:包含演练剧本,验收清单,处置流程图还有常见问题排查,你可以把它当成演练脚本来用,或者说当成运维交付的架构支撑也是没问题的。

@[toc]
一、演练目标与边界(先把“恢复到哪里”说清楚)
做演练的时候,最怕的就是有两件事没给说清楚:
- 目标没弄清:到底要恢复到哪个时间点啊?又要恢复到哪个库里去啊?
- 边界没弄清:在恢复的过程里面,允不允许去覆盖原来的库啊?能不能停机啊?
所以这块的话,我就直接给出一个标准的模板了(大伙可以直接复制过去填空):
| 项目 | 值(示例) |
|---|---|
| 演练对象 | backup_lab |
| 演练方式 | 恢复到新库 backup_lab_drill |
| 事故类型 | 误删表(DROP TABLE backup_demo.t_order) |
| 恢复策略 | 归档格式逻辑备份 + sys_restore 精准恢复 |
| 目标指标 | RPO ≤ 24h,RTO ≤ 30min(示例) |
| 验收标准 | 对象齐全、行数一致、关键聚合一致 |
| 回滚策略 | 演练在新库,不影响原库;失败可重做 |
1.1 角色分工(把“谁来做”写清楚,预案才可交付)
| 角色 | 主要职责 | 交付物 |
|---|---|---|
| DBA/数据库运维 | 执行恢复、分析日志、给出恢复点建议 | 恢复操作记录、恢复耗时、问题清单 |
| 系统运维 | 服务启停、目录权限、磁盘空间、任务计划 | 系统侧日志、磁盘/权限确认 |
| 业务方/测试 | 业务验收、关键报表/接口验证 | 验收结果、异常描述、签字确认 |
二、演练流程图
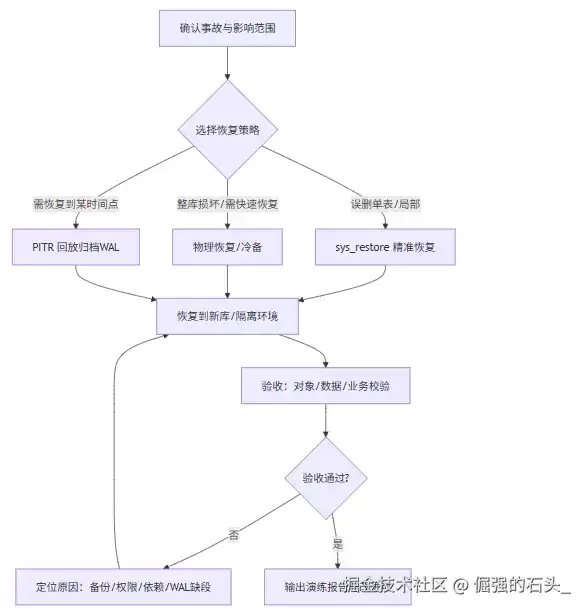
三、案例脚本清单
那么为了让演练可以重复去搞,还能复用,通常来说建议把“造数据—制造事故—验收”这一套给拆成脚本的清单:
01_prepare_env.sql- 去创建演示库、模式还有表
- 往里面插点演示数据
02_business_increment.sql- 备份完了之后新增的数据(这个是用来验证“精准恢复不会去覆盖其他表”的情况)
03_incident_drop_table.sql- 模拟出个事故来:
DROP TABLE backup_demo.t_order;
- 模拟出个事故来:
04_acceptance_check.sql- 验收用的 SQL:查查对象清单、行数,还有关键的聚合数据
05_cleanup.sql- 把演练库
backup_lab_drill给清理掉(这样下次演练的时候还能接着用)
- 把演练库
四、演练记录表(让 RTO/RPO 可量化、可复盘)
演练搞完以后,你“凭感觉说恢复用了 20 分钟”,这其实没啥说服力。那更靠谱一点的搞法是啥呢?也就是说,咱们得边演练边做记录。
| 时间点 | 动作 | 负责人 | 证据(日志/截图) | 备注 |
|---|---|---|---|---|
| T0 | 确认事故与恢复目标 | |||
| T1 | 确认备份文件与可读性 | sys_restore -l 输出 | ||
| T2 | 创建演练库(隔离) | SQL 执行记录 | ||
| T3 | 执行恢复 | 恢复日志文件 | ||
| T4 | 执行验收 SQL | 查询结果截图/日志 | ||
| T5 | 业务验收通过 | 业务签字/记录 | ||
| T6 | 输出演练报告与改进项 | 报告文档 |
四、演练剧本(按时间线写,照做即可)
4.1 T0:演练前准备(5~10 分钟)
1)先确认备份文件是不是存在,而且大小合不合理(看个示例):
D:KB_LABbackuplogicalYYYYMMDD_HHMM_backup_lab_full.dump
2)接着要先“列出归档内容”,确认一下这个备份集里面,是不是真的包含了你要的目标对象:
cd /d D:ToolsKingbaseESServerbin
sys_restore -l D:KB_LABbackuplogical<dump>.dump > D:KB_LABlogs<dump>.list.txt
3)准备一下演练的目标库(搞个新库隔离开来):
cd /d D:ToolsKingbaseESServerbin
ksql -U system -d kingbase -h 127.0.0.1 -p 54321
DROP DATABASE IF EXISTS backup_lab_drill;
CREATE DATABASE backup_lab_drill WITH TEMPLATE = template0 ENCODING = 'UTF8';
4)把“演练的目标指标”(也就是 RPO/RTO)先给定下来,并且记到本子上:
- RPO:这次允许丢失的数据窗口有多大(比如 ≤ 24h)
- RTO:这次允许的恢复耗时是多久(比如 ≤ 30min)
RPO/RTO 这俩东西可不是喊喊口号就行的,它们得能被“备份频率 + 实际恢复耗时 + 验收结果”给撑得住才行。
4.2 T1:恢复到新库(10~30 分钟,视数据量)
接着用 sys_restore 把备份给恢复到演练库里去:
sys_restore -h 127.0.0.1 -p 54321 -U system -d backup_lab_drill D:KB_LABbackuplogical<dump>.dump
4.3 T2:制造事故(演练用)
连上演练库,然后咱们去制造一个“误删表”的事故出来:
ksql -U system -d backup_lab_drill -h 127.0.0.1 -p 54321
DROP TABLE backup_demo.t_order;
dt backup_demo.*
4.4 T3:执行应急恢复(精准恢复)
从同一份备份集里面,咱们仅仅只恢复 t_order 这张表:
sys_restore -h 127.0.0.1 -p 54321 -U system -d backup_lab_drill -t backup_demo.t_order D:KB_LABbackuplogical<dump>.dump
4.5 T4:恢复后验收(必须做)
在 ksql 里面去执行下面的验收项(这是个示例):
dt backup_demo.*
SELECT COUNT(*) AS account_cnt FROM backup_demo.t_account;
SELECT COUNT(*) AS order_cnt FROM backup_demo.t_order;
SELECT SUM(balance) AS total_balance FROM backup_demo.t_account;
如果你想让验收变得更“运维化”一点的话,我通常来说建议把验收给拆成三层来做:
- 层 1:对象层(看看 schema/table/index 这些是不是都齐了)
- 层 2:数据层(查查行数、关键的聚合数据一不一致)
- 层 3:业务层(跑跑关键查询和关键报表,看还能不能用)
4.6 T5:形成“可交付预案”(演练产出不止一份库)
那应该有啥呢?其实是这些:
1)一份恢复操作的记录(里面有命令、路径、耗时还有日志)
2)一份验收的记录(包含 SQL 结果、业务校验、通过标准这些)
3)一份改进的清单(比如自动化、监控、保留策略、权限规范这些东西)
五、验收清单
| 验收项 | 验收方法 | 通过标准 |
|---|---|---|
| 备份集可读 | sys_restore -l | 能列出对象清单,无报错 |
| 目标库可连接 | ksql -d backup_lab_drill | 连接成功 |
| 表对象存在 | dt backup_demo.* | 目标表存在 |
| 行数一致 | COUNT(*) | 行数与预期一致 |
| 关键聚合一致 | SUM/COUNT | 聚合结果一致 |
| 恢复过程可追溯 | 日志文件/任务计划记录 | 有开始/结束时间与结果 |
六、验收的“高频漏项”
很多时候恢复失败,往往仅仅不是因为“表没回来”,而是“表虽然回来了,但是用起来感觉不对劲”。这里就有 4 个常见的漏项:
1)索引还在不在(这会影响性能还有业务体验的)
2)约束或者外键还在不在(这会影响数据一致性的)
3)序列对不对(这会影响自增主键写入的)
4)权限对不对(这会影响应用账户去访问的)
对应的最小检查动作(看个示例):
di+ backup_demo.*
d backup_demo.t_order
六、常见失败场景与处理建议
失败 1:恢复时报权限不足
处理建议:
- 统一用管理员用户去执行恢复操作(比如用
system) - 或者说提前在目标库里面,把需要的权限和所有者给准备好
失败 2:只恢复单表后外键/依赖报错
处理建议:
- 先去把依赖链上游的对象给恢复了(像父表、类型、函数这些)
- 或者说你干脆升级一下,搞个“按 schema 恢复”,别光去恢复单表了
失败 3:备份存在但不可用(文件损坏/格式不匹配)
处理建议:
- 日常做完备份之后,顺手跑个
sys_restore -l,做个快速的可读性检查 - 每周最好搞一次恢复演练,免得等真出事了,才发现“备份根本没法用”
失败 4:PITR 找不到 WAL 段(归档缺失)
处理建议:
- 把归档目录给弄到监控里面去:盯好容量、文件增长还有失败次数
- 明确一下“归档留存周期”,这个周期必须得把“基线备份到目标时间点”这段时间给覆盖住才行
七、演练报告模板
- 演练时间:YYYY-MM-DD HH:MM
- 演练人员:xxx
- 演练对象:backup_lab
- 事故类型:误删表
- 恢复策略:逻辑备份+ sys_restore 精准恢复(或者搞 PITR)
- RPO/RTO 目标:RPO=xx,RTO=xx
- 实际恢复耗时:xx 分钟
- 验收结果:通过/不通过
- 问题与改进:
- 备份耗时还得优化
- 恢复脚本得固化下来
- 归档目录得加上监控
八、把演练变成制度
- 每周搞一次小演练:恢复到新库,再跑跑验收 SQL(用的时间短,但是收益大)
- 每季度搞一次大演练:里面得包含应急沟通、切换还有业务验收签字
- 每次演练必须得产出点改进项出来,而且要在下次演练之前给关掉(这样才能形成闭环)
总结
写到这一篇的时候,其实你已经把“备份恢复”从单纯的操作层面,给提升成“可交付能力”了:
-
有策略(RPO/RTO 的目标很清晰)
-
有流程(有那种可视化的处置路径)
-
有演练(去恢复到新库,做隔离验证)
-
有验收(有可以量化的通过标准)
复盘的时候也把问题的自动化还有监测部分给包含进去了。这样的话,《备份与复原实战》这个系列的7篇文章,也就算是完成了一个大循环了。咱们聊的东西,涉及到了入门级的逻辑备份,精确复原,物理备份,PITR,自动化,还有操作演习验证这些方面。这几乎就是运维场景里面最常被用到,也是非常重要的一套能力集合了。要是大伙还有啥别的问题的话,其实是可以在我这里留言,或者私信我也行。